
Tietokantojen perusteet
"miten tietoa sekä siihen liittyviä yhteyksiä mallinnetaan ja hallinnoidaan?"
Sisältö, aikataulu, arvostelu
"Kurssilla tutustutaan tiedon esitysmuotoihin ja tiedon hakuun suurista tietomääristä. Erityisenä painopisteenä ovat relaatiotietokannat, joiden kohdalla perehdytään toisaalta teoreettiseen perustaan ja toisaalta tietokannan käytännön käsittelyyn SQL-kielen avulla. Kurssilla opitaan myös perustiedot relaatiotietokantojen suunnittelusta."
Huom! Sisältö, aikataulu ja arvostelu koskee Helsingin yliopiston kesän 2017 kurssia.
Kurssi sisältää viisi kotitehtäväsarjaa. Tehtävät tulee tehdä ennen viikoittaisia harjoitustilaisuuksia. Harjoitustilaisuuksissa hyödynnetään kotitehtävien tekemisessä kertynyttä osaamista paikan päällä pohdittavissa suunnittelu- ja toteutustehtävissä.
Arvostelu
Kurssin arvostelu perustuu kurssikokeeseen, harjoitustehtäviin, harjoitustyöhön, sekä läsnäoloon harjoitustilaisuuksissa:
- Kurssikokeessa on kolme tehtävää, joista yksi on 10 pisteen ja kaksi 12 pisteen arvoisia. Kokeesta voi saada yhteensä 34 pistettä. Käytössä on koeleikkuri, eli kurssin hyväksytty suoritus vaatii vähintään puolia koepisteistä.
- Tekemällä harjoituksissa läpikäytäviä ennalta tehtäviä harjoitustehtäviä, saa 0-2 pistettä harjoituskertaa kohden, riippuen tehtyjen tehtävien määrästä. Ennalta tehtävien harjoitustehtävien tekemisestä voi saada yhteensä 10 pistettä.
- Kurssin toisella viikolla muodostetaan 3-5 hengen pienryhmät kurssilla tehtävää tietokannan suunnittelu- ja toteutustehtävää varten. Tehtävä palautetaan kurssin kuluessa kahdessa osassa (ensimmäinen osa 5.6. klo 18:00 mennessä, toinen osa 19.6. klo 18:00 mennessä). Suunnittelu- ja toteutustehtävästä voi enimmillään saada 9 pistettä, myöhästyneistä palautuksista vähennetään aina yksi piste alkavaa päivää kohti. Pienryhmätyön saa halutessaan tehdä myös yksin, mutta se ei ole suositeltavaa.
- Suunnittelu- ja toteutustehtävä arvioidaan sekä kanssaopiskelijoiden että henkilökunnan toimesta. Vertaisarviointiin osallistumisesta saa enimmillään 2 pistettä.
- Harjoitustilaisuuksissa paikan päällä tehtävien tehtävien tekemiseen osallistumisesta saa yhden pisteen harjoituskertaa kohden. Läsnäoloista voi saada yhteensä 5 pistettä.
- Muutamia väliin jääneitä pisteitä voi korvata mittavammalla itsenäisesti tehtävällä harjoitustehtävällä.
Koko kurssista voi saada 60 pistettä. Alustavat arvosanarajat ovat seuraavat:
- 31p -> 1
- 36p -> 2
- 41p -> 3
- 46p -> 4
- 51p -> 5
Lisämateriaali
Tämän materiaalin lisäksi täydentävänä materiaalina voi käyttää Harri Laineen Tietokantojen perusteet -kurssin oppimateriaalia (osa 1, osa 2 ja osa 3), sekä kirjoja "Fundamentals of database systems" (Elmasri & Navathe) ja "Database management systems" (Ramakrishnan & Gehrke). Molemmat löytyvät opiskelijakirjastosta.
Edellä mainittujen kirjojen ostaminen ei ole tätä kurssia varten suositeltavaa.
Esitietovaatimukset
Kurssilla on esitietovaatimuksena kurssi Ohjelmoinnin perusteet. Myös kursseista Ohjelmoinnin jatkokurssi ja Ohjelmistotekniikan menetelmät on kurssilla hyötyä.
Muiden auttaminen ja kunniasääntö
Vaikka helpoin vastaus avunpyyntöön on usein valmiiden ratkaisujen jakaminen, on se sekä toisen että oman oppimisen kannalta erittäin huono lähestymistapa. Opit parhaiten tutkimalla apua kysyvän ongelmaa ja tarjoamalla sellaista tukea, minkä avulla toinen ymmärtää ongelman ja pystyy etenemään. Osallistumalla kurssille sitoudut siihen, että et vie oppimisen iloa muilta esimerkiksi laittamalla tehtävien mallivastauksia verkkoon tai jakamalla niitä muille. Autat muita kurssilaisia parhaiten tekemällä tehtäviä yhdessä muiden kanssa, tarjoamalla apua harjoitustilaisuuksissa sekä osallistumalla teemaan liittyviin keskusteluihin vaikkapa kurssin IRC-kanavalla.
Luennot ja harjoitustilaisuudet
Kurssin aloitusluento järjestetään perjantaina 5.5.2017 klo 16-18 Exactumin luentosalissa CK112.
Kurssilla on viikoittaiset harjoitusryhmät, jotka järjestetään Exactumin salissa B221. Harjoitusryhmiin ilmoittautuminen tapahtuu kurssi-ilmoittautumisen yhteydessä. Harjoitukset alkavat viikolla 20, eli ensimmäiset harjoitustilaisuudet ovat tiistaina 16.5. ja torstaina 18.5.
IRC-ohjeet
Kurssilla on käytössä IRC-kanava #tikape -- ohjeita IRC:n käyttöön löytyy muunmuassa Fuksiwikistä sekä mooc.fi:stä (valitse kanavaksi #tikape).
Pikaohjeita
Puuttuvia pisteitä korvaava tehtävä
Kotona tehtävät tehtäväsarjat
- Kurssin ensimmäinen viikko
- Kurssin toinen viikko
- Kurssin kolmas viikko
- Kurssin neljäs viikko
- Kurssin viides viikko
Paikan päällä tehtävät tehtäväsarjat
- Kurssin ensimmäinen viikko
- Kurssin toinen viikko
- Kurssin kolmas viikko
- Kurssin neljäs viikko
- Kurssin viides viikko
Ryhmätyö
Ryhmät muodostetaan toisissa laskuharjoituksissa, ole siis paikalla!
Kurssikoe
Kurssin koe järjestetään Avoimen yliopiston käytänteiden mukaisesti. Koetilaisuudet ovat ennen kurssin alkua olevan tiedon mukaan ma 19.6.2017 klo 17-20, la 19.8.2017 klo 9-12 ja ma 11.9.2017 klo 17-20. Koepaikan ja koekäytännöt saat tietää Avoimen kautta. Tarkista ajat ja paikat tenttipäivän lähestyessä Avoimen sivuilta muutosten varalta! Kokeeseen saa tuoda mukana käsin kirjoitetun kaksipuolisen A4-kokoisen lunttilapun. Lunttilappu tulee palauttaa kokeen yhteydessä.
Viikko 1
Johdanto
Kävellessäsi Helsingin keskustassa näet ihmisvilinän, kuulet puheensorinan, huomaat uutisotsikoita, mainostauluja ja erilaisia laitteita, jotka tarjoavat monipuolista tietoa sinua ympäröivästä maailmasta. Vaikka tämä toiminta voi tuntua satunnaiselta, voit havaita siitä erilaisia sääntöjä ja hahmoja. Ihmiset kulkevat paikasta toiseen tietoisten tai tiedostamattomien tavoitteiden ohjaamina. Puhe tapahtuu tietyllä kielellä, jolla on oma kielioppi. Uutisotsikoilla on tietynlainen tekstityyli. Mainostaulut hakevat näytettävän mainoksen verkon yli, ja laitteet -- esimerkiksi kännykkäsi -- seuraavat niihin ohjelmoituja sääntöjä, osittain antamiesi komentojen ohjaamana.
Nämä säännöt ja hahmot kuvaavat tiedon rakennetta. Osa tiedosta on jäsentelemätöntä, eli sille ei ole tarkasti määriteltyä muotoa. Esimerkiksi puheensorina voi poukkoilla teemasta toiseen, ja vastaavasti tietoisten ja tiedostamattomien tavoitteiden tarkka kirjaaminen olisi, ainakin, hyvin haastavaa.
Toisaalta, voit lukea saman uutisen lähes sanasta sanaan lehdestä, kännykästäsi tai netistä, olettaen että uutispalvelun tarjoaja on sama. Uutinen on jäsennelty otsikkoon, johdantoon, ja tekstikappaleisiin sekä niihin liittyviin väliotsikkoihin. Eri järjestelmät näyttävät tämän tiedon eri tavalla, ja samalla tarjoavat uutistietoon erilaisen pääsyn. Toimittaja muokkaa ja katsoo uutista sen kirjoittamiseen tarkoitetun sisällönhallintajärjestelmän kautta, kännykällä uutista lukeva saattaa nähdä uutisen kännykän ominaisuuksiin mukautuvan web-sivuston kautta, ja uutisia listaava uutissivusto saattaa listata uutisesta vain sen otsikon.
Puhekielessä termillä tietokanta tarkoitetaan yleisesti ottaen tiedon tallentamiseen tarkoitettua paikkaa, josta tietoa voi myös hakea. Esimerkiksi kirkonkirjat voidaan nähdä eräänlaisena sukujen historiaa dokumentoivana tietokantana, jonka kautta sukututkija pääsee käsiksi sukunsa historiaan. Vaikka tietokannat ovat digitalisaation myötä siirtymässä paperisesta muodosta sähköiseen muotoon, on niiden tavoite pysynyt pitkälti samana: haluamme säilöä tietoa, ja haluamme päästä tähän tietoon käsiksi. Tällä kurssilla käsittelemme elektronisia tietokantoja, joiden kehittyminen on johtanut tilanteeseen, missä tietoa tallennetaan yhä enemmän ja sitä halutaan hyödyntää yhä monipuolisemmin.
Nykyään tietokantoja on kaikkialla. Tämä kurssimateriaali sijaitsee tietokannassa, kurssitehtäviin liittyvät pisteet kirjataan tietokantaan, ja tehdessäsi kurssilla tarpeeksi töitä kurssiin liittyvien oppimistavoitteiden saavuttamiseksi kurssista kirjataan suoritusmerkintä tietokantaan. Jo pelkästään nykyaikaisessa kännykässäsi on kymmeniä erilaisia tietokantoja; yhteystiedot, kalenteri, herätyskello, aikavyöhykkeet, karttapalvelut, suosikkiverkkosivut, jonka lisäksi moni kännykkäsovellus hyödyntää yhtä tai useampaa tietokantaa. Tietokannat voivat olla paikallisia, eli ne voivat sijaita samalla koneella tietokantaa käyttävän ohjelmiston kautta, esimerkiksi kännykässä, tai ne voivat sijaita erillisellä palvelimella, johon otetaan tarvittaessa yhteyttä. Loppukäyttäjän näkökulmastasi tällä ei kuitenkaan ole juurikaan merkitystä. Näet tietokannasta haetun tiedon käyttämäsi sovelluksen tarjoaman näkymän kautta.
Käytämme tällä kurssilla yhtenä esimerkkinä opiskelun ja oppimisen seuraamiseen tarkoitettua järjestelmää, joka kehittyy materiaalin edetessä. Järjestelmä pitää kirjaa kursseista, opiskelijoista, kurssiharjoituksista, arvosanoista, kurssipalautteista, sekä muista oleellisista asioista, joita kurssin edetessä tulee esille. Jotta tämä onnistuisi, tarvitsemme jonkinlaisen jäsentelytavan eli rakenteen tallennettavalle tiedolle, tapoja tiedon tallentamiseen tässä sovitussa muodossa, sekä tapoja erilaisten raporttien luomiseen. Katsotaan miten käy..
Tietokanta ja tiedon rakenteen kuvaaminen
Tietokanta on kokoelma tiettyyn aihepiiriin liittyviä säilytettäviä tietoja. Tietokannan luominen liittyy usein jonkinlaisen organisaation, yrityksen tai muun yhteisön tarpeeseen säilöä ja hakea tietoa. Esimerkiksi yliopisto haluaa pitää kirjaa opiskelijoistaan ja heidän opintomenestystään, hotelli haluaa pitää kirjaa hotellin huoneiden varauksista, ja kauppaketju haluaa pitää kirjaa asiakkaistaan ja asiakkaiden ostoksista.
Tallennettava tieto liittyy tyypillisesti johonkin tavoitteeseen. Yliopisto haluaa seurata opintojen etenemistä esimerkiksi valtionhallinnolle raportointia varten, huoneiden varaustilannetta seuraava hotelli taas haluaa tietää milloin huoneita on paljon tarjolla, ja milloin huoneet ovat lopussa. Kauppaketjun ensisijaisena tavoitteena on asiakkaiden ostosten seuranta myynnin optimoimiseksi.
Tietokantojen rakennetta ja jäsentelyä suunniteltaessa ongelmaa lähestytään tavoitteeseen liittyvien käsitteiden kautta, joiden avulla pyritään ymmärtämään mikä tiedosta on epäoleellista, ja mikä tulee säilöä. Samalla mietitään myös säilöttävien käsitteiden ominaisuuksia sekä käsitteiden suhteita. Esimerkiksi opiskelijan opintomenestyksen seurannassa oleellisia ovat ainakin käsitteet Opiskelija ja Kurssisuoritus, joilla on yhteys: opiskelijalla on kurssisuorituksia.
Tällä kurssilla tiedon mallintamiseen käytetään UML-kieltä, johon syvennytään tarkemmin kurssilla Ohjelmistotekniikan menetelmät. Käytämme luokkakaavioista johdettua tapaa käsitteiden ominaisuuksien ja suhteiden mallintamiseen, mutta, emme kuitenkaan seuraa kuvaustapaa pilkuntarkasti. Esimerkiksi navigointisuuntaa sekä kooste- ja kompositiomerkintää ei käytetä lainkaan.

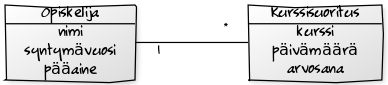
Jos haluamme ilmaista, että käsite liittyy toiseen käsitteeseen, piirrämme käsitteiden välille viivan. Viivan kumpaankin päätyyn merkitään osallistumisrajoitteet, joilla kuvataan sitä, että kuinka monessa samantyyppisessä yhteydessä käsitteen ilmentymä voi olla. Jos ilmentymään voi liittyä tasan yksi toisen tyyppinen ilmentymä, lisäämme viivan toisen tyyppisen ilmentymän päähän numeron yksi. Toisaalta, jos ilmentymien määrä on rajoittamaton, lisäämme viivan päähän tähden. Alla olevassa kaaviossa on käsitteet Opiskelija ja Kurssisuoritus, sekä viiva käsitteiden välillä. Yhteen kurssisuoritukseen liittyy aina tasan yksi opiskelija, mutta yhdellä opiskelijalla voi olla useampia kurssisuorituksia.

Käsitteisiin kuuluu tyypillisesti ominaisuuksia. Ominaisuudet merkitään laatikkoon käsitteen nimen alle. Alla olevassa kuvassa Opiskelija-käsitteeseen liittyy ominaisuudet nimi, syntymävuosi ja pääaine.

Myös kurssisuoritukseen liittyy ominaisuuksia. Alla opiskelijaan liittyy useita kurssisuorituksia, jonka lisäksi käsitteisiin liittyvät ominaisuudet on myös merkitty.
Kun piirrät kaavioita, älä käytä piirtämiseen liikaa aikaa. Oleellisinta on se, että tärkeät asiat ovat paperilla. Jos huomaat, että käytät liikaa aikaa, heitä paperi roskiin, ja aloita alusta.
Käsitteitä ja niiden sisältämää tietoa voidaan ajatella tauluna, jossa jokainen rivi kuvaa yksittäistä käsitteen ilmentymää.
Opiskelija
| nimi | syntymävuosi | pääaine |
|---|---|---|
| Pihla | 1997 | Tietojenkäsittelytiede |
| Joni | 1993 | Tietojenkäsittelytiede |
| Anna | 1991 | Matematiikka |
| Krista | 1990 | Tietojenkäsittelytiede |
| Matti | 1970 | Matematiikka |
| Gandhi | 1869 | Oikeustiede |
Vastaavasti myös kurssisuorituksia kuvaamaan voisi tehdä oman erillisen taulun.
Tietokannanhallintajärjestelmä
Tietokanta sijaitsee tyypillisesti tietokannanhallintajärjestelmässä, jonka kautta tietokantaan pääsee käsiksi. Tietokannanhallintajärjestelmän vastuulla on tietokantaan kohdistuvien haku-, muokkaus- ja lisäystoimintojen toiminnan lisäksi käyttöoikeuksien valvominen. Yksittäisessä tietokannanhallintajärjestelmässä voi kustannus- ja tehokkuussyistä sijaita useisiin erilaisiin sovelluksiin ja käyttötarkoituksiin liittyviä tietokantoja, joita jokaista käyttää eri käyttäjät tai eri yritys.
Yksittäinen sovellus voi käyttää myös useampaa tietokantaa, jotka sijaitsevat eri tietokannanhallintajärjestelmissä. Tyypillinen esimerkki tällaisesta sovelluksesta on analytiikkapalvelu, joka yhdistää eri palveluiden tallentamaa tietoa yhteenvetoraporttien luomiseksi.
Tietokannanhallintajärjestelmän vastuulla on myös tiedon eheyteen liittyvien sääntöjen noudattamisen valvonta. Tietokannassa voi olla esimerkiksi sääntö "Opiskelijan syntymävuoden tulee sisältää neljä numeroa", jolloin uusien opiskelijoiden lisääminen ilman oikein määriteltyä syntymävuotta ei voida lisätä tietokantaan. Vastaavia sääntöjä voidaan lisätä muunmuassa varausjärjestelmiin, esimerkiksi lentokoneiden paikkavarausjärjestelmissä halutaan varmistaa, että jokaisella istuimella on korkeintaan yksi varaus. Vastaavasti, tietokannanhallintajärjestelmän vastuulla on varmistaa, että tietoa ei tuhoudu, vaikka tietokantaa käyttävä järjestelmä hajoaisi -- erilaiset varmuuskopiotoiminnallisuudet ovat tyypillisiä.
Tämän lisäksi, tietokannanhallintajärjestelmät tarjoavat tyypillisesti välineitä tiedon hakemiseen liittyvien toimintojen tehokkuuden tarkastelemiseen. Vaikka opintojen seurantaan liittyvä järjestelmämme sisältäisi tiedot kaikista Helsingin yliopiston opiskelijoista (n. 35000), sekä kaikista kurssisuorituksista (rutkasti), tulisi tietokantaan tehtävien kyselyjen toimia silti mielekkäässä ajassa. Edellämainittukin tietomäärä on esimerkiksi Amazon-verkkokaupan mittakaavassa hyvin pieni.
Vaikka tietokantaa käyttävän sovelluksen tehokkuuteen vaikuttaa tietokone tai palvelin, jolle sovellus on asennettu, emme tällä kurssilla ota juurikaan kantaa ns. rautatason toimintaan.
Johdanto relaatiomalliin ja relaatiotietokantoihin
Relaatiomallin perusajatus on tallennettavan tiedon jakaminen käsitteisiin sekä käsitteiden välisiin yhteyksiin. Jokaista käsitettä vastaa relaatiotietokannassa taulu, ja jokaiselle käsitteen ominaisuudelle eli attribuutille on taulussa oma sarake. Jokainen taulun rivi vastaa yhtä käsitteen ilmentymää, ja tietokantatauluja määriteltäessä taululle määritellään tyypillisesti myös avain, jonka perusteella kukin rivi -- eli käsitteen ilmentymä -- voidaan yksilöidä.
Kun pohdimme Opiskelija-käsitettä, jolla on nimi, syntymävuosi, ja pääaine, huomaamme, että opiskelijan yksilöinti olemassaolevien tietojen perusteella on lähes mahdotonta. Esimerkiksi vuonna 1991 syntyneitä matematiikkaa opiskelevia Anna-nimisiä opiskelijoita löytyy useampia.
Luodaan Opiskelija-käsitteestä tietokantataulu. Tietokantataulussa opiskelija-käsitteelle määritellään opiskelijan yksilöivä avain, jonka lisäksi muut käsitteeseen liittyvät attribuutit lisätään tietokantataulun sarakkeiksi. Tietokantataulun voi piirtää kaaviona kuten alla -- yksilöivän avaimen voi merkitä joko alleviivaamalla käsitteen, tai merkitsemällä käsitteen eteen merkki (pk), eli primary key.
![[Opiskelija|(pk) opiskelijanumero;nimi;syntymävuosi;pääaine]](img/johdanto/opiskelija-ja-opiskelijanumero.png)
Tietokantataulussa oleva data voi näyttää esimerkiksi seuraavalta:
Opiskelija
| opiskelijanumero | nimi | syntymävuosi | pääaine |
|---|---|---|---|
| 9999999 | Pihla | 1997 | Tietojenkäsittelytiede |
| 9999998 | Joni | 1993 | Tietojenkäsittelytiede |
| ... |
Opiskelija-käsitteeseen liittyy useampi Kurssisuoritus, mikä näyttää käsitekaaviona seuraavalta -- allaolevassa käsitekaaviossa Opiskelijaan on lisätty opiskelijanumero:

Relaatiotietokannoissa käsitteiden yhdistäminen tapahtuu avainten avulla. Tietokantatauluun Opiskelija on määritelty jokaisen opiskelijan yksilöivä avain opiskelijanumero. Koska jokaiseen opiskelijaan voi liittyä useampi kurssisuoritus, mutta jokaiseen kurssisuoritukseen vain yksi opiskelija, voimme lisätä kurssisuoritustaulua luodessa siihen viiteavaimen (foreign key), joka viittaa opiskelijaan. Kurssisuoritus-tauluun lisätään siis sarake nimeltä opiskelija, joka sisältää aina kurssisuoritukseen liittyvän opiskelijan opiskelijanumeron. Viiteavain merkitään tekstillä (fk), eli foreign key, ja viiteavaimen nimen jälkeen tulee Taulun nimi, johon viiteavain viittaa.
![[Opiskelija|(pk) opiskelijanumero;nimi;syntymävuosi;pääaine]1-*[Kurssisuoritus|(fk) opiskelija: Opiskelija;kurssi;päivämäärä;arvosana]](img/johdanto/opiskelija-opiskelijanumerolla-ja-kurssisuoritus-taulut.png)
Tietokantataulussa Kurssisuoritus oleva data näyttää esimerkiksi seuraavalta:
Kurssisuoritus
| opiskelija | kurssi | päivämäärä | arvosana |
|---|---|---|---|
| 9999999 | Ohjelmoinnin perusteet | 1.8.2014 | 5 |
| 9999999 | Ohjelmoinnin jatkokurssi | 1.8.2014 | 5 |
| 9999999 | Tietokantojen perusteet | 20.10.2014 | 3 |
| ... | |||
| 9999998 | Ohjelmoinnin perusteet | 1.8.2013 | 4 |
| ... |
Ylläolevat taulut voidaan määritellä myös tekstimuodossa seuraavasti:
- Opiskelija((pk) opiskelijanumero, nimi, syntymävuosi, pääaine)
- Kurssisuoritus((fk) opiskelija -> Opiskelija, kurssi, päivämäärä, arvosana)
Opiskelijan opiskelijanumeroon on lisätty määre (pk), sillä se on Opiskelija-taulun avain. Kurssisuoritustaulun merkintä (fk) opiskelija -> Opiskelija taas tarkoittaa, että opiskelija on viiteavain, joka viittaa Opiskelija-taulun avaimeen.
Pohditaan seuraavaksi kyselyiden tekemistä näihin tauluihin.
SQL-kyselykieli
SQL on jo 80-luvulla standardoitu kyselykieli relaatiotietokantojen käsittelyyn. Sen avulla voidaan hakea tietoa tietokannasta, päivittää tietokannassa olevaa tietoa, sekä muokata ja luoda tietokannan rakennetta. Käytännössä kaikki relaatiotietokantoja tukevat tietokannanhallintajärjestelmät käyttävät myös SQL-kieltä. Vuosien mittaan standardista on kuitenkin julkaistu useita versioita, joista tätä kirjoittaessa viimeisin on vuodelta 2011. Eri tietokannanhallintajärjestelmät ja niiden eri versiot noudattelevatkin standardia vaihtelevissa määrin, eivätkä ole täysin yhteensopivia. On siis syytä huomioida että tietokannanhallintajärjestelmästä toiseen vaihdettaessa usein joudutaan tekemään SQL-kyselyihin muutoksia.
Tässä kurssimateriaalissa keskitymme pääasiassa SQLiten SQL-murteeseen.
Parhaiten kyselykieltä ymmärtää sitä harjoittelemalla. Sitä teemme tällä kurssilla paljon.
SELECT * FROM Taulu
Avainsanalla SELECT valitaan tietyt sarakkeet kyselyn kohteena olevasta taulusta. Sarakkeet määritellään SELECT-avainsanan jälkeen. Jos ohjelmoija haluaa valita kaikki taulussa olevat sarakkeet, käytetään sarakkeiden valinnassa tähteä (*). Sarakkeiden määrittelyä seuraa avainsana FROM, jonka jälkeen kerrotaan kyselyn kohteena oleva taulu.
Alla voit kokeilla kyselyn tekemistä aiemmin määriteltyihin Opiskelija ja Kurssisuoritus-tauluihin.
Tehtävät
Tee nyt kysely, jolla saat listattua kaikki Kurssisuoritus-taulussa olevat rivit.
SELECT sarake, toinen FROM Taulu
Avainsanan SELECT jälkeen voidaan määritellä valittavat sarakkeet. Tähteä käyttämällä valitaan kaikki sarakkeet, mutta ohjelmoija voi valita myös yksittäisiä sarakkeita. Jos tähteä ei käytetä, ja halutaan valita useampia sarakkeita, valittavat sarakkeet erotellaan pilkulla.
Tehtävät
Tee nyt kysely, jolla saat listattua Kurssisuoritus-taulussa olevien kurssien nimet.
SELECT DISTINCT sarake FROM Taulu
Kun haimme edellisessä harjoitteluosiossa Kurssisuoritus-taulussa olevien kurssien nimiä, huomasimme, että muutamat kurssien nimet näkyivät useampaan otteeseen. Tämä johtuu siitä, että kysely valitsee taulun rivit, ja taulussa yksinkertaisesti oli useampia rivejä, joilla esiintyi samat kurssit.
Avainsanalla DISTINCT voidaan valita vain uniikit vastausrivit. Avainsana DISTINCT tulee avainsanan SELECT jälkeen.
Tehtävät
Tee nyt kysely, jolla saat listattua Kurssisuoritus-taulussa olevat uniikit kurssit.
SELECT * FROM Taulu WHERE...
Emme tyypillisesti kuitenkaan halua valita kaikkea taulussa olevaa dataa, vaan vain tietyt hakuehdot täyttävän osajoukon. Avainsanan WHERE avulla kyselyille annetaan hakuehtoja. Hakuehtojen perusteella kyselyn tulokseen valitaan vain ne rivit, joissa hakuehdossa määritellyn sarakkeen arvot täyttävät hakuehdon. Hakuehto voi olla esimerkiksi muotoa ...WHERE nimi = 'Joni', jolloin valittaisiin vain ne rivit, joissa sarakkeen nimi arvo on 'Joni'.
Tehtävät
Tee nyt kysely, jolla saat listattua Opiskelija-taulusta kaikki ne opiskelijat, joiden nimi on 'Anna'.
Tee nyt kysely, jolla saat listattua Kurssisuoritus-taulusta kaikki Pihla-nimisen opiskelijan suoritukset. Voit olettaa, että Opiskelija-taulun sisältö on täsmälleen se, kuin mikä se tähän asti on ollut. Vinkki: millä Pihlan tunnistaa kummassakin taulussa?
Kyselyissä toimivat myös suurempi kuin > ja pienempi kuin < -operaatiot.
Jos sarakkeen arvot ovat merkkijonoja, kuten kurssin nimi ja opiskelijan nimi, voi hakuehdossa käyttää myös LIKE-operaatiota. Tämän avulla hakutuloksia voi rajata osittaisen merkkijonon avulla. Esimerkiksi kysely SELECT * FROM Opiskelija WHERE nimi LIKE '%a%' hakee kaikki opiskelijat, joiden nimessä esiintyy a-kirjain.
Tehtävät
Tee nyt kysely, jolla saat listattua kaikki Opiskelija-taulussa olevat pääaineet, joissa esiintyy sana "tiede".
Huom! Tee kysely siten, että näet vain uniikit vastaukset. Kyselyn vastauksessa pitäisi olla vain 2 riviä. Kun saat kyselyn toimimaan, kokeile mitä tapahtuu jos muutat 'LIKE'-operaation muotoon 'NOT LIKE'.
Erilaiset yhteystyypit
Huomaamme, että käsite Kurssisuoritus oikeastaan liittyy kahteen eri asiaan; kurssiin ja kurssin suoritukseen. Eriytetään nämä kaksi käsitettä toisistaan.
Kurssiin liittyy kurssin yleiset tiedot kuten kurssin nimi, kurssikoodi, sekä kurssin kuvaus. Kurssisuoritus taas liittyy tiettyyn kurssiin, opiskelijaan, päivämäärään, arvosanaan, sekä opintopistemäärään. Opintopistemäärä pidetään osana kurssisuoritusta, sillä joillain kursseilla opintopistemäärä vaihtelee työmäärästä riippuen. Käsite Opiskelija säilyy sellaisenaan.
Yhteen kurssisuoritukseen liittyy aina yksi kurssi, mutta yhteen kurssiin voi liittyä monta kurssisuoritusta. Käsitekaaviona tämä näyttää seuraavalta:

Tutkitaan ensin ylläolevan kaavion osaa, missä kurssisuoritukseen liittyy yksi kurssi ja yhteen Kurssiin monta kurssisuoritusta. Emme hetkeen välitä Opiskelija-käsitteen olemassaolosta. Sekä kurssisuoritukselle että kurssille on määritelty niihin liittyvät attribuutit.
![[Kurssisuoritus|päivämäärä;arvosana;opintopistemäärä]*-1[Kurssi|nimi;kuvaus]](img/johdanto/kurssisuoritus-kurssi-attrs.png)
Luodaan seuraavaksi Kurssisuorituksesta ja Kurssista tietokantataulut.
Ensimmäinen askel on tietokantataulun Kurssi luominen sekä sen pääavaimen määrittely. Kurssin nimi ei ole hyvä avain, sillä esimerkiksi kurssin nimi "Tietokone työvälineenä" toistuu eri tiedekunnissa ja laitoksissa useiden erilaisten kurssien nimenä. Toisaalta, avaimen on hyvä olla sellainen, että se ei muutu -- (jos avain muuttuisi, kaikki viiteavaimet tulisi myös päivittää) -- kuvauskaan ei ole hyvä avain. Luodaan avainta varten uusi attribuutti, kurssitunnus, ja lisätään se tauluun muiden kurssikäsitteeseen liittyvien attribuuttien kanssa.
![[Kurssi|(pk) kurssitunnus;nimi;kuvaus]](img/viikko2/kurssi-paaavaimella.png)
Luodaan tämän jälkeen taulu Kurssisuoritus. Koska jokaiseen kurssisuoritukseen liittyy yksi kurssi, luodaan tauluun viiteavain kurssi, joka viittaa Kurssi-tauluun. Muut attribuutit lisätään tauluun viiteavaimen lisäksi.
![[Kurssi|(pk) kurssitunnus;nimi;kuvaus]](img/viikko2/kurssisuoritus-viiteavaimella.png)
Yhdistetään tietokantataulut vielä viivalla.
![[Kurssisuoritus|(fk) kurssi: Kurssi;päivämäärä;arvosana;opintopistemäärä]*-1[Kurssi|(pk) kurssitunnus;nimi;kuvaus]](img/viikko2/kurssisuoritus-ja-kurssi-tietokantataulut.png)
Kolmannen tietokantakaulun lisääminen tietokantakaavioon
Tarkastellaan seuraavaa käsitekaaviota, ja tehdään siitä seuraavaksi tietokantakaavio.
![[Opiskelija|opiskelijanumero;nimi;syntymävuosi;pääaine] 1-* [Kurssisuoritus|päivämäärä;arvosana;opintopistemäärä]
[Kurssisuoritus] *-1 [Kurssi|nimi;kuvaus]](img/viikko2/opiskelija-kurssisuoritus-kurssi-luokkakaavio.png)
Teimme edellä jo käsitteistä Kurssi ja Kurssisuoritus tietokantakaavion, joten voimme keskittyä nyt käsitteiden Opiskelija ja Kurssisuoritus väliseen suhteeseen.
Aloitamme taas käsitteestä, jonka viivan päässä on 1, eli tässä tapauksessa opiskelijasta. Kuten aiemmin, käytämme tietokantataululle Opiskelija avaimena opiskelijanumeroa, sillä se yksilöi jokaisen opiskelijan.
Keskitytään tämän jälkeen viivan toiseen päähän, eli tässä tapauksessa käsitteeseen Kurssisuoritus. Koska yhteen kurssisuoritukseen liittyy tasan yksi opiskelija, lisätään tauluun Kurssisuoritus viiteavain opiskelija, joka viittaa opiskelijaan. Muuten taulu pysyy samana kuten aiemminkin.
Voimme nyt yhdistää kaikki taulut yhteen, jolloin tietokantakaavio on seuraavanlainen:
![[Opiskelija|(pk) opiskelijanumero;nimi;syntymävuosi;pääaine]1-*[Kurssisuoritus|(fk) opiskelija: Opiskelija;(fk) kurssi: Kurssi;päivämäärä;arvosana;opintopistemäärä]
[Kurssisuoritus]*-1[Kurssi|(pk) kurssitunnus;nimi;kuvaus]](img/viikko2/opiskelija-kurssisuoritus-kurssi-tietokantakaavio.png)
Yhteystyypit jatkuu: kursseihin liittyy tehtäviä
Haluamme, että järjestelmämme voi pitää kirjaa myös kursseihin liittyvistä tehtävistä, joita opiskelija voi suorittaa. Koska kurssiin liittyvien tehtävien määrä voi vaihdella, määritellään yhteys siten, että yhteen kurssiin voi liittyä useita tehtäviä. Toisaalta, koska sama tehtävä voi esiintyä useammalla kurssilla, määritellään yhteys siten, että yhteen tehtävään liittyä useampi kurssi.
![[Tehtävä] *-* [Kurssi]](img/johdanto/tehtava-kurssi.png)
Yllä kuvattu yhteystyyppi on monen suhde moneen.
Tarkastellaan uudestaan käsitteiden tehtävä ja kurssi yhteyttä, ja muunnetaan käsitekaavio tietokantakaavioksi.
Ensimmäinen askel on taulujen luominen sekä niihin liittyvien avainten määrittely. Olemme aiemmin luoneet taulun käsitteestä kurssi, sekä määritelleet sille pääavaimen, joten keskitymme vain taulun Tehtävä luomiseen.
Määritellään, että tehtävään liittyy nimi ja kuvaus. Kumpikaan niistä ei sovellu tehtävän avaimeksi, joten luodaan tehtävälle avain tunnus, joka yksilöi jokaisen tehtävän. Käsitteestä Tehtävä luotu tietokantataulu on seuraavanlainen:
![[Tehtävä|(pk) tunnus;nimi;kuvaus]](img/viikko2/tehtava-tietokantataulu.png)
Luodaan seuraavaksi liitostaulu, jonka tehtävänä on yhdistää taulut Tehtävä ja Kurssi. Kutsutaan liitostaulua nimellä Kurssitehtävä. Kurssitehtävä-taululla on kaksi viiteavainta, joista toinen osoittaa tauluun Tehtävä, ja toinen tauluun Kurssi.
![[Kurssitehtävä|(fk) tehtävä: Tehtävä; (fk) kurssi: Kurssi]](img/viikko2/kurssitehtava-liitostaulu.png)
Lisätään seuraavaksi yhteydet käsitteiden välille -- tämä tapahtuu lähinnä visualisoinnin takia, viitteet ovat todellisuudessa olemassa jo viiteavainten muodossa. Yhteen Kurssitehtävä-taulun riviin liittyy tasan yksi Kurssi-taulun rivi ja Tehtävä-taulun rivi, mutta yksi Kurssi-taulun rivi voi liittyä moneen Kurssitehtävä-taulun riviin -- samoin kuin yksi Tehtävä-taulun rivi voi liittyä moneen Kurssitehtävä-taulun riviin.
Tietokantakaavio on lopulta seuraavanlainen:
![[Tehtävä|(pk) tunnus;nimi;kuvaus]1-*[Kurssitehtävä|(fk) tehtävä: Tehtävä; (fk) kurssi: Kurssi]
[Kurssitehtävä]*-1[Kurssi|(pk) kurssitunnus;nimi;kuvaus]](img/viikko2/monesta-moneen-tehtava-kurssitehtava-kurssi.png)
Useammassa taulussa olevan tiedon yhdistäminen
Hahmottelimme edellisessä luvussa opiskelun ja oppimisen seuraamiseen tarkoitetun järjestelmämme tietokantaa. Päädyimme yhteystyyppien käsittelyssä kahteen tietokantakaavioon, jotka ovat seuraavat:
Voimme yhdistää tietokantakaaviot suoraan, sillä kumpikin kaavio sisältää taulun Kurssi. Tietokantakaavio, missä kaikki taulut ovat yhdessä, näyttää seuraavalta:
![[Opiskelija|(pk) opiskelijanumero;nimi;syntymävuosi;pääaine]1-*[Kurssisuoritus|(fk) opiskelija: Opiskelija;(fk) kurssi: Kurssi;päivämäärä;arvosana;opintopistemäärä]
[Kurssisuoritus]*-1[Kurssi|(pk) kurssitunnus;nimi;kuvaus]
[Tehtävä|(pk) tunnus;nimi;kuvaus]1-*[Kurssitehtävä|(fk) tehtävä: Tehtävä; (fk) kurssi: Kurssi]
[Kurssitehtävä]*-1[Kurssi|(pk) kurssitunnus;nimi;kuvaus]](img/viikko2/tietokantakaavio.png)
Voit tutkia uudessa esimerkkitietokannassa olevaa tietoa allaolevan SQL-komentotulkin avulla.
Tutustuimme aiemmin SQL-kyselyihin, joiden avulla teimme erilaisia kyselyitä yksittäisiin tietokantatauluihin. Tutustutaan seuraavaksi erääseen tapaan useammassa taulussa olevan tiedon yhdistämiseen.
Aiempaa materiaalia kertaamalla muistamme, että avainsanaa FROM seuraa taulu, josta tietoa haetaan. Voimme määritellä haun kohteeksi useampia tauluja listaamalla ne FROM-avainsanan jälkeen pilkulla eroteltuna seuraavasti SELECT * FROM Opiskelija, Kurssisuoritus. Jos emme kerro miten taulujen rivit yhdistetään, on lopputuloksessa kaikki rivit yhdistettynä kaikkiin riveihin -- esimerkiksi jokainen taulun Opiskelija rivi yhdistettynä jokaiseen taulun Kurssisuoritus riviin.
Yllä esitetyn kyselyn tuottama lopputulos ei ole tyypillisesti tavoiteltu -- jokaiseen opiskelijaan on kytketty jokainen kurssisuoritus, eli kaikilla on kaikki kurssisuoritukset.
Taulujen yhdistäminen tapahtuu kyselyä rajaavan WHERE-ehdon avulla siten, että taulun pääavainta verrataan siihen viittaavan taulun viiteavaimeen. Esimerkiksi, jos haluamme vain kurssisuoritukset ja niihin liittyvät opiskelijat, hyödynnämme Opiskelija-taulun avainta opiskelijanumero sekä Kurssisuoritus-taulun viiteavainta opiskelija, joka viittaa Opiskelija-taulun pääavaimeen. Käytännössä tämä tapahtuu ehdolla WHERE Opiskelija.opiskelijanumero = Kurssisuoritus.opiskelija.
Kokonaisuudessaan lause "Anna kaikki riviyhdistelmät tauluista Opiskelija ja Kurssisuoritus, joissa attribuuttien opiskelijanumero ja opiskelija arvot ovat samat" kirjoitetaan seuraavasti: SELECT * FROM Opiskelija, Kurssisuoritus WHERE Opiskelija.opiskelijanumero = Kurssisuoritus.opiskelija.
Tehtävät
Tee nyt kysely, joka tulostaa jokaisen opiskelijan nimen, kurssisuorituksen päivämäärän, ja kurssisuorituksen arvosanan.
Useamman taulun yhdistäminen
Useamman taulun yhdistäminen onnistuu samalla tavalla. Kaikki taulut, jotka haluamme lisätä kyselyyn, tulevat FROM-avainsanan jälkeen. Jos tauluja on useampi, on hyvä varmistaa, että kaikki taulut yhdistetään avainkenttien perusteella, sillä muuten haun vastaus voi olla iso.
Kun yhdistämme useampia tauluja, päädymme helposti tilanteeseen, missä tuloksessa on myös useampia samannimisiä kenttiä. Esimerkiksi omassa tietokantamäärittelyssämme kenttä nimi löytyy tauluista Tehtävä, Kurssi ja Opiskelija. Voimme määritellä taulun, mihin haettava kenttä liittyy, pisteoperaattorin avulla. Kyselyn SELECT nimi FROM Opiskelija voi siis kirjoittaa myös muodossa SELECT Opiskelija.nimi FROM Opiskelija.
Voimme toisaalta myös nimetä kentän tulostusmuodon seuraavasti SELECT Opiskelija.nimi AS opiskelija FROM Opiskelija. Edelläoleva kysely hakee Opiskelija-taulusta opiskelijan nimen, mutta tulostaa nimet otsikolla 'opiskelija'.
Allaoleva kysely listaa jokaiselta opiskelijalta opiskelijan nimen sekä opiskelijan suorittamat kurssit.
Tehtävät
Tee nyt kysely, joka tulostaa jokaiseen kurssiin liittyvän tehtävän. Tulostuksen otsikoiden nimien tulee olla 'kurssi' ja 'tehtävä'.
Voit kokeilla juuri rakennettua kyselyä alla.
Opiskelijan tekemät tehtävät
Voimme hakea kurssiin liittyvät tehtävät, kurssiin liittyvät opiskelijat, sekä opiskelijan mahdollisesti tekemät tehtävät, jotka saadaan hakemalla kaikkiin opiskelijan kursseihin liittyvät tehtävät. Emme kuitenkaan saa selville yksittäisen opiskelijen tekemiä tai tekemättä jättämiä tehtäviä.
Jotta tuleva opintojen seurantaan liittyvä järjestelmämme toimisi mielekkäästi, lisätään tietokantaan mahdollisuus opiskelijan ja tehtyjen tehtävien yhdistämiseen. Voimme yhdistää opiskelijan joko tehtävään tai kurssiin liittyvään tehtävään.
Jos opiskelija yhdistetään tehtävään, opiskelijan tekemä tehtävä näkyy merkittynä kaikilla tehtävää käyttävillä kursseilla. Tämä ei kuitenkaan ole aina toivottua, sillä tehtäviä käytetään myös kertaamistarkoituksessa. Linkitetään siis opiskelija kurssitehtävään: yksi opiskelija voi suorittaa monta kurssitehtävää, ja yhden kurssitehtävän voi suorittaa monta opiskelijaa -- yhteys on monen suhde moneen -tyyppinen.
Tiedämme miten toimia. Koska Opiskelija-taulussa on pääavain, avainta ei tarvitse määritellä siihen. Kurssitehtävä-taulussa pääavainta ei ole, joten määritellään sille pääavain -- kutsutaan avainta nimellä tunnus. Luodaan tämän jälkeen liitostaulu, jonka tehtävänä on kytkeä Opiskelija-taulun ja Kurssitehtävä-taulun rivejä, ja sitä kautta pitää kirjaa suorituksista. Kutsutaan liitostaulua nimellä Tehtäväsuoritus, ja määritellään sille viiteavaimet tauluun Opiskelija ja tauluun Kurssitehtävä. Lisätään tämän lisäksi tauluun myös kenttä suoritusaika, johon merkitään tehtävän suoritusaika.
Taulu Tehtäväsuoritus näyttää seuraavanlaiselta:
![[Tehtäväsuoritus|(fk) opiskelija: Opiskelija; (fk) tehtävä: Kurssitehtävä; suoritusaika]](img/viikko3/taulu-tehtavasuoritus.png)
Yhteen tehtäväsuoritukseen liittyy yksi opiskelija, mutta opiskelijalla voi olla monta tehtäväsuoritusta. Samoin, yhteen tehtäväsuoritukseen liittyy yksi kurssitehtävä, mutta yhteen kurssitehtävään voi liittyä monta tehtäväsuoritusta. Kokonaisuudessaan tietokantakaaviomme on nyt seuraavanlainen:
![[Opiskelija|(pk) opiskelijanumero;nimi;syntymävuosi;pääaine]1-*[Kurssisuoritus|(fk) opiskelija: Opiskelija;(fk) kurssi: Kurssi;päivämäärä;arvosana;opintopistemäärä]
[Kurssisuoritus]*-1[Kurssi|(pk) kurssitunnus;nimi;kuvaus]
[Tehtävä|(pk) tunnus;nimi;kuvaus]1-*[Kurssitehtävä|(pk) tunnus; (fk) tehtävä: Tehtävä; (fk) kurssi: Kurssi]
[Kurssitehtävä]*-1[Kurssi|(pk) kurssitunnus;nimi;kuvaus]
[Tehtäväsuoritus|(fk) opiskelija: Opiskelija; (fk) tehtävä: Kurssitehtävä; suoritusaika]
[Tehtäväsuoritus]*-1[Opiskelija]
[Tehtäväsuoritus]*-1[Kurssitehtävä]](img/viikko3/tietokantakaavio-tehtavasuorituksella.png)
Opiskelijan tekemien tehtävien hakeminen
Nyt opiskelijan tekemien tehtävien hakeminen on suoraviivaisempaa. Hahmotellaan kysely, joka hakee kaikki opiskelijat, jotka ovat tehneet tietokantojen perusteet -kurssin tehtäviä, sekä näiden opiskelijoiden tekemät tehtävät. Muotoillaan tulostus siten, että tuloksessa on opiskelijan nimi ja opiskelijan tekemän tehtävän nimi.
Aloitetaan hakemalla Kurssi-taulusta kurssi Tietokantojen perusteet.
SELECT * FROM Kurssi WHERE nimi = 'Tietokantojen perusteet';
Kytketään seuraavaksi kyselyn tulos tauluun Kurssitehtävä, eli haetaan kaikki kurssitehtävät, joissa kurssina on Tietokantojen perusteet.
SELECT * FROM Kurssi, Kurssitehtävä
WHERE Kurssi.nimi = 'Tietokantojen perusteet'
AND Kurssi.kurssitunnus = Kurssitehtävä.kurssi;
Liitetään kyselyyn tämän jälkeen taulu Tehtävä, jonka kautta saamme tehtävien nimet.
SELECT * FROM Kurssi, Kurssitehtävä, Tehtävä
WHERE Kurssi.nimi = 'Tietokantojen perusteet'
AND Kurssi.kurssitunnus = Kurssitehtävä.kurssi
AND Tehtävä.tunnus = Kurssitehtävä.tehtävä;
Tulostetaan välitarkastuksena tehtävien nimet:
SELECT Tehtävä.nimi AS Tehtävä
FROM Kurssi, Kurssitehtävä, Tehtävä
WHERE Kurssi.nimi = 'Tietokantojen perusteet'
AND Kurssi.kurssitunnus = Kurssitehtävä.kurssi
AND Tehtävä.tunnus = Kurssitehtävä.tehtävä;
Kyselyn tulos on seuraava -- tuntuu toimivan.
| Tehtävä |
|---|
| Onko tässä rekursio? |
| Keksi tehtävä |
| Koetus |
Lisätään kyselyyn tämän jälkeen taulu Tehtäväsuoritus, jonka kautta pääsemme kohta Opiskelija-tauluun.
SELECT Tehtävä.nimi AS Tehtävä
FROM Kurssi, Kurssitehtävä, Tehtävä, Tehtäväsuoritus
WHERE Kurssi.nimi = 'Tietokantojen perusteet'
AND Kurssi.kurssitunnus = Kurssitehtävä.kurssi
AND Tehtävä.tunnus = Kurssitehtävä.tehtävä
AND Tehtäväsuoritus.tehtävä = Kurssitehtävä.tunnus;
Lisätään lopulta kyselyyn vielä Opiskelija-taulu, ja haetaan sieltä opiskelijan nimi. Voit kokeilla tuloksena olevaa kyselyä alla.
Tehtävät
Tee nyt kysely, joka tulostaa kaikki tehtävät, jotka opiskelija 'Anna' on suorittanut. Tee tulostuksesta sellainen, että yksi sarake sisältää kurssin nimen, ja toinen sarake tehtävän nimen.
Useammassa taulussa olevan tiedon yhdistäminen JOIN-kyselyillä
Kyselyssä, missä taulujen rivit yhdistetään WHERE-ehdon ja avainten perusteella, valitaan näytettäväksi vain ne rivit, jotka täyttävät annetun ehdon. Esimerkiksi, voimme hakea kaikki kurssit ja ne tehneet opiskelijat seuraavasti:
Entä jos haluaisimme nähdä myös ne kurssit, joita kukaan ei ole suorittanut? Tämä ei ratkea, ainakaan suoraviivaisesti.
Vuonna 1992 julkaistu SQL-standardin versio toi mukanaan JOIN-kyselyt, joiden avulla edellä määritelty ongelma ratkeaa -- pienen harjoittelun kautta. Tutustutaan seuraavaksi aiemmin oppimaamme taulujen yhdistämistapaa tukeviin erityyppisiin JOIN-kyselyihin.
INNER JOIN
Aiemmin tutuksi tullut kysely SELECT * FROM Opiskelija, Kurssisuoritus WHERE Opiskelija.opiskelijanumero = Kurssisuoritus.opiskelija valitsee vastaukseen vain ne rivit, joiden kohdalla ehto Opiskelija.opiskelijanumero = Kurssisuoritus.opiskelija pätee, eli missä Opiskelija-taulun opiskelijanumero-sarakkeen arvo on sama kuin Kurssisuoritus-taulun opiskelija-sarakkeen arvo.
Edellinen kysely voidaan kirjoittaa myös muodossa SELECT * FROM Opiskelija INNER JOIN Kurssisuoritus ON Opiskelija.opiskelijanumero = Kurssisuoritus.opiskelija.
Jos haluamme kyselyyn useampia tauluja, lisätään ne INNER JOIN -komennon avulla kyselyn jatkoksi. Esimerkiksi kaksi seuraavaa kyselyä ovat toiminnallisuudeltaan samankaltaiset.
SELECT Kurssi.nimi AS Kurssi, Opiskelija.nimi AS Opiskelija
FROM Kurssi, Kurssisuoritus, Opiskelija
WHERE Kurssi.kurssitunnus = Kurssisuoritus.kurssi
AND Kurssisuoritus.opiskelija = Opiskelija.opiskelijanumero;
Kyselyn INNER JOIN avulla voimme siis tehdä kutakuinkin saman työn kuin aiemman WHERE-ehdon avulla, eli valita mukaan vain ne rivit, joiden kohdalla ehto pätee.
LEFT JOIN
Mikä tekee taulujen liitoksesta JOIN-kyselyn avulla WHERE-ehtoa monipuolisemman, on se, että JOIN-kyselyn avulla voidaan määritellä kyselyehtoa täyttämättömille riveille toiminnallisuutta. Avainsanalla LEFT JOIN voidaan määritellä kyselyn tulos sellaiseksi, että ehdon täyttävien rivien lisäksi vastaukseen sisällytetään kaikki FROM-avainsanaa seuraavan taulun rivit, joille liitosehto ei täyttynyt.
Allaoleva kysely listaa kurssisuorituksia keränneiden opiskelijoiden lisäksi myös opiskelijat, joilla ei ole kurssisuorituksia. Tällöin kurssisuoritukseen liittyvä vastauksen osa jää tyhjäksi.
Niiden kurssien listaus, joilla on kävijöitä, tai joilla ei ole kävijöitä onnistuu myös esimerkiksi seuraavasti.
Liitostyypit lyhyesti
Kyselyn JOIN-tyypin voi muotoilla usealla eri tavalla:
INNER JOIN-- palauta vain ne rivit, joihin valintaehto kohdistuu.LEFT JOIN-- palauta kaikki FROM-komentoa seuraavan taulun rivit, ja liitä niihin LEFT JOIN-komentoa seuraavan taulun rivit niiltä kohdin, kuin se on ON-liitosehdossa määritellyn ehdon mukaan mahdollistaRIGHT JOIN-- palauta kaikki RIGHT JOIN-komentoa seuraavan taulun rivit, ja liitä niihin FROM-komentoa seuraavan taulun rivit niiltä kohdin, kuin se on ON-liitosehdossa määritellyn ehdon mukaan mahdollistaFULL JOIN-- palauta kaikki FROM-komentoa seuraavan taulun rivit sekä kaikki FULL JOIN-komentoa seuraavan taulun rivit, ja liitä ne toisiinsa niiltä kohdin, kuin se on ON-liitosehdossa määritellyn ehdon mukaan mahdollista
Valitettavasti tällä sivulla käytössä oleva kyselyiden harjoitteluun tarkoitettu apuväline ei tue RIGHT JOIN ja FULL JOIN -tyyppisiä kyselyitä.
Tietokantarivien lisääminen ja poistaminen
Kyselyiden lisäksi on tärkeää pystyä sekä lisäämään rivejä tauluihin, että poistamaan rivejä tauluista.
Rivien poistaminen taulusta
Rivien poistaminen tietokantataulusta tapahtuu komennon DELETE FROM avulla, mitä seuraa taulun nimi, mistä poistetaan tietoa, sekä WHERE-ehto, millä määritellään ehdot, joihin osuvat rivit poistetaan.
Esimerkiksi, opiskelija nimeltä 'Gandhi' voidaan poistaa seuraavalla komennolla.
DELETE FROM Opiskelija WHERE nimi = 'Gandhi'
Rivien lisääminen tauluun
Rivien lisääminen tietokantatauluun tapahtuu komennon INSERT INTO avulla, mitä seuraa kohdetaulun nimi. Taulun jälkeen määritellään sarakkeet, joihin arvot asetetaan, jota seuraa uudelle riville lisättävät arvot.
Esimerkiksi, uusi Kurssi nimeltä 'Web-selainohjelmointi', jonka kurssitunnus on 582354 lisätään tauluun seuraavalla komennolla. Lisäyksen
INSERT INTO Kurssi (kurssitunnus, nimi, kuvaus)
VALUES (582354,
'Web-selainohjelmointi',
'Web-sovellusten selainpuolen toiminnallisuuden toteuttamisen perustekniikoita');
Toisaalta, uuden opiskelijan -- Jack Bowerin -- lisääminen tapahtuu seuraavasti:
Uusien rivien lisäämiseen on myös toinen merkintätapa. Jos jokaiseen taulun sarakkeeseen ollaan lisäämässä arvo, ei sarakkeiden nimiä tarvitse erikseen kertoa.
Viikko 2
Käsiteanalyysi
Käsiteanalyysia (conceptual modeling) käytetään tutkittavaan aihepiiriin tai ongelma-alueeseen liittyvien käsitteiden sekä niiden välisten yhteyksien selvittämiseen. Käsite voidaan määritellä löyhästi jonkinlaisena asiana, jonka nykyinen olemassaolo ei vaadi jonkun muun asian olemassaoloa -- jos asia on olemassaoloriippuvainen, se on mahdollisesti hyvä attribuuttiehdokas. Esimerkiksi Henkilön nimi ei ole tässä mielessä käsite, sillä henkilön nimi on riippuvainen henkilön olemassaolosta. Toisaalta, Henkilö taas on käsite, sillä sen olemassaolo ei vaadi jonkun muun asian olemassaoloa. Käsitteet voidaan tyypillisesti myös erottaa toisistaan jollain tavalla, tai niille tulee olla vähintäänkin mahdollista määritellä jonkunlainen yksilöivä tunnus.
Käsitteiden välisillä yhteyksillä taas tarkoitetaan esimerkiksi käsitteiden välisiä suhteita, esimerkiksi Henkilöllä voi olla sisaruksia sekä vanhemmat, ja henkilö voi vaikkapa opiskella jossain opinahjossa.
Seuraamme tällä kurssilla kurssin Ohjelmistotekniikan menetelmät luentomonisteessa esitettyä menetelmää käsiteanalyysiin. Siinä missä kurssilla ohjelmistotekniikan menetelmät puhutaan luokkaehdokkaista, puhumme tällä kurssilla käsitteistä. Kurssi ohjelmistotekniikan menetelmät linjaa seuraavat askeleet käsitteiden eriyttämiseen:
- Kartoita käsite-ehdokkaita
Laadi luettelo tarkasteltavan ilmiön kannalta keskeisistä kohteista tai ilmiöistä, jotka voisivat tulla kyseeseen käsitteinä. Tällaisia voisivat olla toimintaan osallistujat, toiminnan kohteet, toimintaan liittyvät tapahtumat, materiaalit, tuotteet ja välituotteet, toiminnalle edellytyksiä luovat asiat.
Kartoituksen pohjana voi käyttää vapaamuotoista tekstikuvausta tarkasteltavasta ilmiöstä, jota kutsutaan jatkossa kohdealueeksi (engl. problem domain). Tästä kuvauksesta alleviivataan käsite-ehdokkaita ja kerätään ne luetteloon. Käsite-ehdokkaat esiintyvät kuvauksessa usein substantiiveina. Alustavaa karsintaa voi tehdä sen perusteella, onko asia lainkaan oleellinen mallinnettavan ilmiön kannalta.
- Karsi ehdokkaita
Luetteloon saadut ehdokkaat käydään läpi ja arvioidaan voisiko ehdokas tulla kyseeseen käsitteenä. Arvioinnissa tulisi tarkastella:
- Liittyykö ilmiöön tietosisältöä, joka on välttämätöntä järjestelmän kannalta.
- Onko asia riittävän tärkeä kohdealueen kannalta.
Karsintaa ja ehdokkaiden kartoitusta joudutaan usein tekemään iteratiivisesti. Ensimmäinen karsintakierros ei välttämättä tuota lopullista tulosta.
- Tunnista käsitteiden väliset yhteydet
Yhteyksiä voi etsiä vapaamuotoisesta kuvauksesta. Yhteyttä ilmaisevat usein verbit, genetiivit, muut kytkentää kuvaavat ilmaukset. Yhteyksienkin suhteen tulisi miettiä onko yhteys oleellinen tarkasteltavan ilmiön kannalta sekä onko se rakenteellinen eli jollain lailla pysyvä ilmiöiden välinen suhde. Yhteyksiksi otetaan ainoastaan merkitykselliset, pysyvämpiluonteiset suhteet ilmiöiden välillä.
- Määrittele yhteyksiin liittyvät osallistumisrajoitteet
Osallistumisrajoitteiden avulla ilmaistaan rakenteellisia sääntöjä. Ne eivät välttämättä tule esiin vapaamuotoisessa kuvauksessa vaan edellyttävät tarkempaa kohdealueen analysointia.
- Täsmennä käsitteitä määrittelemällä attribuutit
Attribuutteja saattaa löytyä vapaamuotoisesta kuvauksesta, mutta yleensä niiden löytäminen edellyttää lisäselvityksiä kohdealueesta, esimerkiksi toiminnan osapuolten haastatteluja. Attribuuttien kohdalla tulee myös selvittää mihin niitä tarvitaan.
Sovelletaan edellisiä askeleita jo nyt tuttuun Uimari-esimerkkiin:
Käsite-ehdokkaiden kartoitus
Eristetään tekstistä keskeiset kohteet, ilmiöt ja käsitteet alleviivaamalla ne tekstistä. Aloitetaan valitsemalla lähes kaikki substantiivit tarkasteltavaksi.
Listataan seuraavaksi alleviivatut termit, ja muunnetaan ne samalla yksikkömuotoon.
- Uimaseura
- Paperi
- Uimari
- Tulos
- Valmennuspäällikkö
- Kirjanpito
- Tietokone
- Seura
- Miesuimari
- Naisuimari
- Selkäuinti
- Laji
- Kilpailu
Ehdokkaiden karsinta
Karsitaan seuraavaksi ehdokkaita.
Uimaseura-- seuralle tehdään järjestelmää, voidaan jättää pois ainakin toistaiseksi.Paperi-- tästä haluttiin päästä eroon, tulokset kirjattiin aiemmin paperille.- Uimari
- Tulos
Valmennuspäällikkö-- valmennuspäällikkö haluaa uuden järjestelmän, mutta ei oleellinen käsite tietomallin kannalta.Kirjanpito-- järjestelmä tulee sisältämään kirjanpidon, mutta kirjanpito ei käsite järjestelmässä.Tietokone-- kts. edellinenSeura-- kts. uimaseura.Miesuimari-- Uimari on valittuna käsitteeksi, sukupuoli voi esim. olla uimarin attribuuttina.Naisuimari-- kts. edellinenSelkäuinti-- Laji on valittuna käsitteeksi.- Laji
- Kilpailu
Ehdokkaiden karsinnan jälkeen seuraavat käsitteet ovat jäljellä:
- Kilpailu
- Laji
- Uimari
- Tulos
Käsitteiden välisten yhteyksien tunnistaminen
Yhteydet tunnistetaan joko tekstistä tai "rivien välistä" aiempaa tietoa käyttämällä. Esimerkiksi lause "Uimarit kilpailevat yleensä yhdessä lajissa.." vihjaavat että (1) uimarit liittyvät lajiin, (2) uimarit liittyvät kilpailuun, ja (3) lajit liittyvät kilpailuun.
Tämän lisäksi, tulokset liittynevät myös uimariin, kilpailuun ja lajiin. Hahmotellaan käsitekaaviota olemassaolevien käsitteiden perusteella.
![[Uimari]-[Laji]
[Laji]-[Kilpailu]
[Kilpailu]-[Uimari]
[Tulos]-[Uimari]
[Tulos]-[Laji]
[Tulos]-[Kilpailu]](img/viikko3/uimari-kasitteet.png)
Yhteyksiin liittyvien osallistumisrajoitteiden määrittely
Kun yhteydet on määritelty, määritellään niille seuraavaksi osallistumisrajoitteet. Osallistumisrajoitteilla tarkoitetaan "viivojen päissä" olevia rajoitteita, joilla kerrotaan esimerkiksi tieto, että yhteen tietyn käsitteen ilmentymään liittyy korkeintaan yksi toinen tietyn käsitteen ilmentymä.
Uimari voi osallistua yhteen tai useampaan lajiin, eli uimariin voi liittyä monta lajia. Toisaalta, yhtä lajia voi harrastaa useampi uimari. Kilpailussa voi olla monta lajia, ja lajia voidaan todennäköisesti uida monessa kilpailussa. Kilpailussa voi olla monta uimaria, ja uimari voi uida useammassa kilpailussa. Yksittäiseen tulokseen taas liittyy yksi uimari, yksi laji, ja yksi kilpailu -- mutta, yhteen uimariin voi liittyä monta tulosta, yhteen lajiin voi liittyä monta tulosta, ja yhteen kilpailuun voi liittyä monta tulosta.
Ehdotus käsitekaavioksi osallistumisrajoitteiden kanssa on seuraavanlainen:
![[Uimari]*-*[Laji]
[Laji]*-*[Kilpailu]
[Kilpailu]*-*[Uimari]
[Tulos]*-1[Uimari]
[Tulos]*-1[Laji]
[Tulos]*-1[Kilpailu]](img/viikko3/uimari-kasitteet-rajoitteilla.png)
Attribuuttien määrittely käsitteisiin
Käsitteisiin liittyvien attribuuttien määrittely tapahtuu sekä haastatteluiden että ongelma-alueen analyysin kautta. Ongelma-alueen tekstimuotoisesta kuvauksesta tiedämme esimerkiksi, että kilpailuilla on paikka ("paikalliset kilpailut", "seuran ulkopuoliset kilpailut"), mutta toisaalta tekstimuotoinen kuvaus ei esimerkiksi kerro kilpailujen järjestämisajankohdasta. Tieto kilpailun ajankohdasta -- ja sitä kautta tulosten ajankohdasta -- on oleellinen uimareiden kehittymisen seurantaan.
Ali- ja yhteenvetokyselyt sekä tilastojen luominen
Osaamme hakea yhdestä tai useammasta tietokantataulusta tietoa, sekä rajata kyselyiden palauttamia tuloksia erilaisilla ehdoilla. On kuitenkin kysymyksiä, joihin vastaaminen nykyisillä työvälineillämme on melko hankalaa. Miten esimerkiksi ratkaisisit seuraavat ongelmat?
- Mitkä tehtävät ovat sellaisia, joita kursseilla heikommin menestyneet opiskelijat -- esimerkiksi hylätyn arvosanan tai ykkösen saaneet -- eivät ole saaneet tehtyä?
- Miten haen opiskelijat, jotka eivät ole vielä osallistuneet yhdellekään kurssille?
- Kuinka monta opiskelijaa pääsi tietyn kurssin läpi?
- Mikä on jokaisen kurssin keskiarvo?
Yhteistä edellä olevilla kysymyksillä on se, että lähes kaikki niistä ovat oikeastaan yhteenvetokyselyjä. Tutustutaan kohta näiden käsittelyyn liittyviin menetelmiin.
Alikyselyt
Alikyselyt ovat nimensä mukaan kyselyn osana suoritettavia alikyselyitä, joiden tuloksia käytetään osana pääkyselyä. Pohditaan kysymystä Miten haen opiskelijat, jotka eivät ole vielä osallistuneet yhdellekään kurssille?, ja käytetään siihen ensin aiemmin tutuksi tullutta tapaa, eli LEFT JOIN -kyselyä. Yhdistetään opiskelijaa ja kurssisuoritusta kuvaavat taulut LEFT JOIN-kyselyllä siten, että myös opiskelijat, joilla ei ole suorituksia tulevat mukaan vastaukseen. Tämän jälkeen, jätetään vastaukseen vain ne rivit, joilla kurssisuoritukseen liittyvät tiedot ovat tyhjiä -- tämä onnistuu katsomalla mitä tahansa kurssisuoritus-taulun saraketta, ja tarkistamalla onko se tyhjä, eli null. Tämä onnistuu seuraavasti:
Toinen vaihtoehto edellisen kyselyn toteuttamiseen on toteuttaa kysely, joka hakee kaikki ne opiskelijat, jotka eivät ole kurssisuorituksia saaneiden opiskelijoiden joukossa. Tässä on oleellisesti kaksi kyselyä: (1) hae opiskelijat, joilla on kurssisuoritus, ja (2) hae opiskelijat, jotka eivät ole edellisen kyselyn palauttamassa joukossa.
Alikyselyn toteuttaminen
Alikyselyn toteuttamiseksi voimme määritellä kyselyn WHERE-osaan sarakkeen nimen, jota seuraa avainsana NOT IN, jota taas seuraa suluissa oleva kysely.
Tee nyt kysely, joka listaa kaikki kurssit, joilla ei ole yhtään tehtävää.
Käytännössä alikyselyt tuottavat kyselyn tuloksena taulun, josta pääkyselyssä tehtävä kysely tehdään. Ylläolevassa esimerkissä alikyselyn tuottamassa taulussa on vain yksi sarake, jossa on kurssisuorituksen saaneiden opiskelijoiden opiskelijanumerot.
Määreen NOT IN, joka tarkastaa että valitut arvot eivät ole alikyselyn tuottamassa taulussa, lisäksi käytössä on määre IN. Määreen IN avulla voidaan luoda ehto, jolla tarkastetaan, että valitut arvot ovat annetussa joukossa tai taulussa. Esimerkiksi alla haetaan kaikki kurssisuoritukset, joissa arvosana on kolme tai viisi.
Yhteenvetokyselyt
Yhteenvetokyselyiden avulla kyselyiden tuloksia ryhmitellään sarakkeissa olevien arvojen perusteella, jonka jälkeen luoduille ryhmille tehdään erilaisia yhteenvetokyselyitä. Voimme esimerkiksi haluta selvittää opiskelijoiden määrän pääaineittain ryhmiteltynä -- toisin sanoen, listata pääaineet ja opiskelijalukumäärät. Kyselyn vastauksessa olevan rivien lukumäärän saa komennolla COUNT(sarake), missä sarake on laskettavan sarakkeen nimi. Ryhmittely tapahtuu komennon GROUP BY-perusteella, jota seuraa sarakkeen nimi, jonka perusteella tulokset ryhmitellään.
Tee nyt kysely, jolla lasket kurssisuoritus-taulussa olevat kurssisuoritukset kurssin koodin perusteella. Käytä tulostuksessa sarekkeiden nimiä "kurssikoodi" ja "lukumäärä".
Useampien taulujen yhdistäminen toimii kuten ennen -- valittavat taulut kerrotaan joko FROM -avainsanan jälkeen tai JOIN -avainsanan jälkeen, riippuen kyselytavasta. Ryhmittelykomento tulee mahdollisten WHERE-ehtojen jälkeen. Alla olevassa esimerkissä lasketaan tehtävien määrä eri kursseilla siten, että kurssin nimi haetaan taulusta Kurssi, ja tehtävät haetaan kurssitehtävistä.
Tee nyt kysely, jossa lasket kurssisuoritus-taulussa olevien kurssien suoritukset -- taas koodin perusteella. Tällä kertaa tulostuksessa tulee kuitenkn tulostaa kurssikoodin sijaan kurssin nimi. Käytä sarakkeiden niminä "kurssi" ja "lukumäärä". (Huomaa, että edellisessä osassa katsotaan kurssitehtäviä, tässä kurssisuorituksia!)
Edellä olevia tuloksia tarkasteltaessamme, huomaamme, että luku nolla ei esiinny yhdelläkään rivillä. Tämä selittyy kyselyillämme -- olemme valinneet mukaan vain rivit, joilla hakuehdot täyttyvät. Hups. Kirjoitetaan edellinen kysely siten, että otamme huomioon kurssit vaikka niihin ei liittyisikään yhtäkään toisen taulun riviä -- käytämme siis LEFT JOIN-liitosoperaatiota.
Tee nyt LEFT JOIN -operaatiota käyttäen kysely, jolla listaat kurssikohtaiset suorituslukumäärät siten, että myös ne kurssit, joilla ei ole yhtäkään suoritusta otetaan huomioon. Käytä sarakkeiden niminä nimiä "kurssi" ja "lukumäärä".
Ryhmittely useamman sarakkeen perusteella
Komennolle GROUP BY voi antaa myös useampia sarakkeita, jolloin se ryhmittelee ne annetussa järjestyksessä. Esimerkiksi ryhmittely GROUP BY kurssi, arvosana ryhmittelisi taulussa olevat rivit ensin kurssin perusteella, jonka jälkeen ne vielä ryhmiteltäisiin arvosanan perusteella. Tällöin jokaiselle kurssille tulisi erilliset arvosanaryhmät. Esimerkiksi kurssikohtaiset arvosanat saisi tulostettua seuraavalla kyselyllä:
Edellisessä kyselyssä on hieman tylsää se, että kurssien nimet ja arvosanat eivät ole järjestyksessä.
Tulosten järjestäminen
Kyselyn tulokset voi järjestää komennolla ORDER BY, jota seuraa järjestettävät sarakkeet. Sarakkeelle voi antaa myös lisämääreen ASC (ascending), joka kertoo että tulokset tulee järjestää nousevaan järjestykseen, ja DESC (descending), joka kertoo että tulokset tulee järjestää laskevaan järjestykseen. Oletuksena järjestys on nouseva.
Komento ORDER BY tulee kyselyn loppuun. Järjestetään edellisen kyselyn tulokset.
Yhteenvetokyselyissä käytettäviä funktioita
Komento COUNT(sarake) on funktio, jolle annetaan joukko arvoja, ja joka palauttaa niiden pohjalta luodun arvon -- annetun joukon koon eli arvojen lukumäärän. Yhteenvetokyselyiden käytössä on myös nippu muita funktioita, joista seuraavassa listataan muutamia.
Keskiarvon laskeminen
AVGFunktio
AVGlaskee sille annettujen arvojen keskiarvon. Esimerkiksi kurssikohtaiset arvosanojen keskiarvot saa laskettua seuraavalla kyselyllä:Summan laskeminen
SUMFunktio
SUMlaskee sille annettujen arvojen summan. Esimerkiksi kysely seuraava kysely laskee opiskelijakohtaisen opintopistemäärän.Kuten ehkä huomaat, kysely ei toimi tapauksissa, missä opiskelija on korottanut kurssin arvosanaa, sillä hänellä on tällöin useampia hyväksyttyjä merkintöjä samasta kurssista.
Pienimmän arvon valitseminen
MINFunktio
MINvalitsee sille annettujen arvojen joukosta pienimmän arvon.Suurimman arvon valitseminen
MAXFunktio
MAXvalitsee sille annettujen arvojen joukosta suurimman arvon.
Hakutulosten rajaaminen yhteenvetokyselyiden perusteella
Jos haluat rajata yhteenvetokyselyn tuloksen perusteella kyselysi palauttamia rivejä, et voi käyttää WHERE-ehtoa tähän. WHERE-ehdon sijaan joudut käyttämään samankaltaista HAVING-ehtoa. Lisätään esimerkiksi edelliseen SUM-kyselyyn rajoitus että haluamme nähdä vain opiskelijat jotka ovat suorittaneet enemmän kuin 10 opintopistettä.
Kuten esimerkissä näkyy, samassa kyselyssä voi olla sekä WHERE-ehto että HAVING-ehto.
Kyselyn tulos on taulu
Kaikki SQL-kyselyt tuottavat tuloksena taulun. Taulussa voi olla tasan yksi sarake ja rivi, tai vaikkapa tuhansia rivejä ja kymmeniä sarakkeita. Silloinkin, kun suoritamme yksinkertaisen haun, kuten vaikkapa "Hae kaikki kurssilla 'Tietokantojen perusteet' olevat opiskelijat", on haun tuloksena taulu.
Kaikki tekemämme SQL-kyselyt ovat liittyneet tauluihin. Emmekö siis voisi tehdä kyselyjä myös vastauksiin? Vastaus on kyllä.
Esimerkiksi vanhimman (tai vanhimmat, jos tämä ei ole yksikäsitteistä) opiskelijat löytää -- muunmuassa -- etsimällä kaikista pienimmän mahdollisimman syntymävuoden (kyselyn tulos on taulu), jonka jälkeen vastaustaulussa olevaa tulosta kaikkien opiskelijoiden syntymävuosiin.
Tietokantataulujen luominen ja muokkaaminen
Tähän mennessä tietokantataulut ovat olleet valmiiksi annettuna, eikä meidän ole tarvinnut pohtia niiden luomista. Tehdään korjausliike, ja tutustutaan tietokantataulujen -- ja sitä kautta -- oman tietokannan rakenteen määrittelyyn ja luomiseen.
Tietokantataulun luominen
Tietokantataulu luodaan SQL-komennolla CREATE TABLE, jota seuraa luotavan taulun nimi, ja suluissa attribuuttien eli sarakkeiden nimet sekä niiden tyypit pilkulla eroteltuna. Tyyppien määrittely ei ole kaikissa tietokannanhallintajärjestelmissä pakollista, jolloin tietokannanhallintajärjestelmä käyttää mahdollista oletustyyppiä.
Luodaan aiemmin tutuksi tullut Opiskelija-taulu.
Opiskelija
| opiskelijanumero | nimi | syntymävuosi | pääaine |
|---|---|---|---|
| 9999999 | Pihla | 1997 | Tietojenkäsittelytiede |
| 9999998 | Joni | 1993 | Tietojenkäsittelytiede |
Taulu opiskelija saadaan luotua SQL-komennolla CREATE TABLE Opiskelija (opiskelijanumero, nimi, syntymävuosi, pääaine) -- emme ota vielä kantaa sarakkeiden tietotyyppeihin, vaan määrittelemme vain nimet. Tällöin tietokannanhallintajärjestelmä ottaa vastuun sarakkeiden tyyppien asettamisesta -- jos se on mahdollista.
Juuri luotuun tauluun saa lisättyä uusia rivejä komennolla INSERT INTO, jota seuraa taulun nimi, sarakkeet suluissa eroteltuna, sekä uudelle riville asetettavat arvot.
Luodussa taulussa olevan tiedon hakeminen tapahtuu kuten ennenkin.
Kurssi-taulun luominen
Luo tietokantaan taulu Kurssi, jolla on sarakkeet kurssitunnus, nimi ja kuvaus.
Lisää nyt tauluun Kurssi kurssi nimeltä "SQL-kielen perusteet", jonka kurssitunnus on "12345" ja kuvaus "SELECT 'Hei maailma';".
Tarkista vielä, että taulun luominen onnistui, ja että uusi kurssi löytyy tietokantataulusta.
Attribuuttien datatyypit
Jokaisella attribuutilla tulee olla nimi sekä datatyyppi. Jos datatyyppiä ei määritellä, voi tietokannanhallintajärjestelmä määritellä sen itse -- esimerkiksi SQLite pyrkii päättelemään attribuutin tyypin dynaamisesti, mutta useimmat tietokannanhallintajärjestelmät eivät tällaista päättelyä tee.
Tietokantaan säilöttävä tieto voi olla montaa eri muotoa, esimerkiksi merkkijonoja, numeroita, binäärimuodossa olevia tiedostoja, sekä päivämääriä. Tietokannan suunnittelijan tehtävänä on päättää, minkämuotoista dataa missäkin sarakkeessa on.
Puhekielessä voidaan puhua sarakkeen tyypistä, sillä sarakkeen tyyppi määrää millaista tietoa sarakkeeseen tallennetaan. Käytännössä tietokantataulua luotaessa sarakkeen määrittelyssä annettavat tiedot kertovat tietokannanhallintajärjestelmälle siitä, että minkälaista tietoa sarakkeeseen voidaan lisätä, ja toisaalta samalla minkälaista tietoa sarakkeeseen ei voida lisätä. Sarakkeen tyyppi vaikuttaa myös toiminnallisuuksiin -- esimerkiksi keskiarvon laskeminen merkkijonotyyppisiä arvoja sisältävästä sarakkeesta ei todennäköisesti ole hyödyllistä.
Tyypilliset datatyypit ovat seuraavat:
- varchar(n) korkeintaan n merkin pituinen merkkijono.
- integer kokonaisluku
- float liukuluku eli desimaaliluku
- date päivämäärä, tallentaa vuoden, kuukauden ja päivän
- timestamp aikaleima, tallentaa vuoden, kuukauden, päivän, tunnit, minuutit ja sekunnit -- mahdollisesti myös tarkempia arvoja
Taulua luodessa sarakkeen tyyppi määritellään lisäämällä datatyypin nimi sarakkeen nimen perään. Esimerkiksi Opiskelija-taulua luodessa opiskelijanumero voitaisiin määritellä kokonaisluvuksi, nimi korkeintaan 200 merkkiä pitkäksi merkkijonoksi, syntymävuosi päivämääräksi ja pääaine korkeintaan 50 merkkiä pitkäksi merkkijonoksi seuraavasti:
CREATE TABLE Opiskelija
(
opiskelijanumero integer,
nimi varchar(200),
syntymävuosi date,
pääaine varchar(50)
)
Nyt -- riippuen käytetystä tietokannanhallintajärjestelmästä -- sarakkeeseen opiskelijanumero ei voisi esimerkiksi lisätä merkkijonoa, sillä se on kokonaisluku. Tämä johtaa tilanteeseen, missä tietokannanhallintajärjestelmä itsessään varoittaa tiedon lisääjää yksinkertaisista virheistä.
Kurssi-taulun luominen sarakkeiden tyypeillä
Luo taulu Kurssi, jolla on sarakkeet kurssitunnus, nimi ja kuvaus. Kurssitunnuksen tulee olla kokonaisluku, nimen merkkijono, ja kuvauksen merkkijono.
Varmista vielä PRAGMA-komennolla, että sarakkeiden tyypit ovat halutut.
Rajoitteet ja avaimet
Kun olemme aiemmin luoneet tietokantakaavioita käsitekaavioista, olemme määritelleet tietokantatauluille yksilöivän pääavaimen. Pääavain on taulukohtainen tunniste, joka on uniikki jokaiselle taulun riville, jonka lisäksi sen arvo ei saa olla tyhjä (null) millään rivillä. Pääavaimeksi valitaan joko olemassaoleva taulun sarake, tai tauluun luodaan uusi sarake.
Pääavaimen määrittely
Pääavain määritellään tietokantataulun luonnin yhteydessä lisäämällä sarakkeen tyypin perään rajoite PRIMARY KEY. Tämä tarkoittaa, että sarakkeen arvo on uniikki, ja että se ei saa koskaan olla tyhjä. Täydennetään aiempaa opiskelijan määrittelyä siten, että opiskelijanumerosta tehdään Opiskelija-taulun pääavain
CREATE TABLE Opiskelija
(
opiskelijanumero integer PRIMARY KEY,
nimi varchar(200),
syntymävuosi date,
pääaine varchar(50)
)
Kokeillaan edelläolevaa komentoa käytännössä.
Lisätään seuraavaksi tietokantatauluun uusi opiskelija nimeltä Ada Lovelace. Seuraavalla komennolla vain tietokantataulun kenttään nimi asetetaan arvo.
Listaa nyt taulussa olevat opiskelijat. Mitä huomaat jos opiskelijoita lisätään tietokantatauluun enemmän?
Koska tietokantatauluun on määritelty avain, joka on uniikki, ei taulun sarakkeessa opiskelijanumero voi olla kahta samaa arvoa. Kokeile tätä painamalla alla olevaa nappia ensin kerran -- jolloin opiskelija lisätään -- ja sitten vielä toisen kerran. Mitä virheviesti kertoo?
Kurssi-taulun luominen sarakkeiden tyypeillä ja pääavaimella
Luo taulu Kurssi, jolla on sarakkeet kurssitunnus, nimi ja kuvaus. Kurssitunnuksen tulee olla kokonaisluku, nimen merkkijono, ja kuvauksen merkkijono. Tämän lisäksi, kurssitunnuksen tulee olla pääavain.
Seuraavan kyselyn useampaan otteeseen suorittamisen pitäisi epäonnistua, sillä tietokantataulun kurssitunnus-sarakkeen pitäisi olla olla pääavain, ja sen takia uniikki.
Jokaisella taululla voi olla vain yksi määritelty pääavain. Joskus kuitenkin haluamme, että pääavain liittyy useampaan sarakkeeseen, jolloin sarakkeiden yhdistelmän tulee olla uniikki. Voimme esimerkiksi haluta rajoittaa opiskelijoiden kurssi-ilmoittautumisia siten, että jokainen opiskelija voi ilmoittautua vain kerran tietylle kurssille. Tämä onnistuisi kuvitteellisen KurssiIlmoittautuminen-taulun kautta siten, että taulun pääavaimena toimisi opiskelijanumeron ja kurssin yhdistelmä.
CREATE TABLE KurssiIlmoittautuminen
(
opiskelijanumero integer,
kurssi integer,
PRIMARY KEY (opiskelija, kurssi)
)
Nyt taulussa KurssiIlmoittautuminen voi olla vain yksi samanlainen opiskelijanumero-kurssi -arvopari, jolloin opiskelija voi ilmoittautua kurssille vain kerran.
Uniikkius ja arvon pakollinen määrittely
Tietokantataulun sarakkeille voidaan määritellä myös muita rajoitteita, kuten se, että sarakkeen arvon tulee olla uniikki, tai että sarakkeessa on pakko olla arvo. Sarakkeen uniikkius määritellään komennolla UNIQUE, joka seuraa tyyppiä. Vastaavasti se, että sarakkeessa on pakko olla arvo määritellään komennolla NOT NULL.
Jos haluamme esimerkiksi lisätä Opiskelija-tauluun rajoitteet, missä määritellään se, että nimeä ja syntymäaikaa ei saa jättää määrittelemättä, lisätään niihin NOT NULL määreet.
CREATE TABLE Opiskelija
(
opiskelijanumero integer PRIMARY KEY,
nimi varchar(200) NOT NULL,
syntymävuosi date NOT NULL,
pääaine varchar(50)
)
Toisaalta, jos määrittelisimme ylläolevan lisäksi säännöt, joiden mukaan nimen ja syntymävuoden tulisi olla uniikkeja, olisi määrittely seuraava.
CREATE TABLE Opiskelija
(
opiskelijanumero integer PRIMARY KEY,
nimi varchar(200) NOT NULL UNIQUE,
syntymävuosi date NOT NULL UNIQUE,
pääaine varchar(50)
)
Tämä ei kuitenkaan olisi kovin fiksua, sillä yllä määriteltävässä taulussa yhdelläkään opiskelijalla ei saisi olla samaa nimeä jonkun toisen kanssa. Vastaavasti, sama syntymävuosi (tai aika) johtaisi virhetilanteeseen.
Viiteavainten määrittely
Tietokantataulujen viiteavaimet ovat sarakkeita, joissa olevat arvot viittaavat toisissa tauluissa oleviin pääavaimiin. Tietokantataulua määriteltäessä viiteavaimet listataan sarakkeiden määrittelyn jälkeen. Jokaisen viiteavaimen yhteydessä kerrotaan sekä luotavan taulun sarake -- eli sarake, joka on viiteavain -- että taulu ja sarake, johon viiteavaimella viitataan. Viiteavaimen määrittely tapahtuu komennolla FOREIGN KEY(sarake) REFERENCES ViitattavaTaulu(viitattavaSarake).
Jos tietokantataulut Opiskelija ja Kurssi ovat määritelty seuraavasti:
CREATE TABLE Opiskelija
(
opiskelijanumero integer PRIMARY KEY,
nimi varchar(200) NOT NULL,
syntymävuosi date NOT NULL,
pääaine varchar(50)
);
CREATE TABLE Kurssi
(
kurssitunnus integer PRIMARY KEY,
nimi varchar(200) NOT NULL,
kuvaus varchar(3000)
);
Voidaan taulu kurssisuoritus, joka viittaa sekä opiskelijaan, että kurssiin, määritellä seuraavasti.
CREATE TABLE Kurssisuoritus
(
opiskelija integer NOT NULL,
kurssi integer NOT NULL,
päivämäärä date NOT NULL,
arvosana integer NOT NULL,
opintopistemäärä integer NOT NULL,
FOREIGN KEY(opiskelija) REFERENCES Opiskelija(opiskelijanumero),
FOREIGN KEY(kurssi) REFERENCES Kurssi(kurssitunnus)
);
Viiteavaimet ovat siis sarakkeita siinä missä muutkin sarakkeet, mutta niille määritellään erikseen rajoitteet, jotka kertovat, että ne ovat viiteavaimia. Taulussa käytettävien viiteavainten määrä ei käytännössä ole rajattu -- voi olla, että niitä ei ole yhtäkään, tai niitä voi olla useita. Yllä viiteavainsarakkeille opiskelija ja kurssi on lisäksi määritelty NOT NULL-rajoitteet, joiden avulla määritellään että sarakkeiden arvot eivät saa jäädä tyhjiksi.
Kokeillaan edellä nähtyä käytännössä. Luodaan ensin tietokantataulut Opiskelija ja Kurssi, sekä lisätään niihin muutama rivi.
Nyt käytössämme on taulut Opiskelija ja Kurssi, jonka lisäksi niissä on kummassakin muutama rivi. Luodaan seuraavaksi taulu Kurssisuoritus, jossa on viiteavaimet kumpaankin edellä mainittuun tauluun.
Nyt käytössä on tietokantataulut Opiskelija, Kurssi, ja Kurssisuoritus. Kurssisuoritus-taulussa on kaksi viiteavainta -- toinen viittaa tauluun Opiskelija, ja toinen tauluun Kurssi. Tutki ensin taulujen Opiskelija ja Kurssi sisältöjä, ja lisää sen jälkeen tauluun Kurssisuoritus suoritusmerkintä kurssista Tikape opiskelijalle Ada. Voit kokeilla ensin mitä tapahtuu, jos et aseta viiteavaimia oikein.
Tehtävän ja Kurssitehtävän lisääminen.
Harjoitellaan edellä nähtyjä asioita vielä hieman. Käytämme pohjana seuraavaa tietokantakaaviota.
Alla olevaan kyselylaatikkoon on määritelty kysely, minkä avulla luodaan tietokantataulu Kurssi sekä lisätään sinne kurssit Ohpe ja Tikape.
Toteuta nyt taulut Kurssitehtävä ja Tehtävä siten, että niissä on määriteltynä sekä pääavaimet että viiteavaimet. Pohdi, missä järjestyksessä taulut tulee toteuttaa, jotta saat viiteavaimet määriteltyä oikein.
Lisää nyt Tehtävä-tauluun muutama rivi, ja määrittele olemassaoleville kursseille muutamia tehtäviä.
Hakuja nopeuttavat indeksirakenteet
Tietokantatauluun kohdistuvissa kyselyissä hakua rajataan ehdoilla. Esimerkiksi kysely SELECT * FROM Taulu WHERE sarake = 'haluttu', hakee kaikki taulussa olevat rivit, joissa annetun sarakkeen 'sarake' arvo on 'haluttu'. Oletuksena tietokantamoottori käy läpi kaikki rivit, ja valitsee niistä vain ne rivin, joissa sarakkeen arvo on haluttu. Jos rivejä on vaikkapa 100 miljoonaa, käydään niistä jokainen yksitellen läpi.
Tietokantakyselyiden tehostamista on tutkittu paljon, ja tietokantamoottorit tarjoavat tyypillisesti erilaisia välineitä kyselyiden tehostamiseksi. Yksi väline on usein toistuvien hakujen tehostamiseen tarkoitettu indeksi, eli hakurakenne.
Pohditaan tilannetta, missä edellisen 100 miljoonaa riviä sisältävän taulun lisäksi tietokannalla on erillinen hakurakenne usein käytetylle sarakkeelle. Hakurakenteessa sarakkeen arvot ovat järjestettynä. Tällöin, tiettyä arvoa haettaessa, voimme aloittaa keskimmäisestä arvosta -- jos haettava arvo on pienempi, tutkitaan "vasemmalla" olevaa puolikasta. Jos taas haettava arvo on suurempi, tutkitaan "oikealla" olevaa puolikasta. Alueen rajaaminen jatkuu niin pitkään, kunnes haettava arvo löytyy, tai rajaus päätyy tilanteeseen, missä tutkittavia arvoja ei enää ole. Tämä menetelmä -- puolitushaku tai binäärihaku lienee jo tuttu kurssilta Ohjelmoinnin perusteet.
Jos rivejä on yhteensä miljardi, voidaan ne jakaa kahteen osaan noin log2 1 000 000 000 kertaa, eli noin 30 kertaa. Jos oletamme, että arvoa ei löydy taulusta, tulee yhteensä tarkastella siis noin 30 riviä aiemman miljardin sijaan.
Indeksin määrittely
Indeksin määrittely tietokantataulun sarakkeelle tapahtuu tietokantataulun luomisen jälkeen komennolla CREATE INDEX, jota seuraa uuden indeksin nimi, avainsana ON, ja sarakkeet, joille indeksi luodaan. Tietokantataulun pääavaimelle ja viiteavaimelle luodaan indeksit automaattisesti.
Oletetaan, että haluaisimme hakea opiskelijoita pääaineen perusteella melko usein, jolloin rajauksen tehokkuudella on hieman väliä. Tehdään siis tauluun Opiskelija erillinen indeksi pääaine-sarakkeelle.
CREATE INDEX idx_paaaine ON Opiskelija (pääaine);
Indeksien nimentä alkaa tyypillisesti sanalla idx, jatkuu alaviivalla sekä sarakkeita kuvaavalla sopivalla nimellä. Jos indeksin haluaa määritellä useammalle sarakkeelle samaan aikaan, voi indeksoitavat sarakkeet listata pilkuilla toisistaan erotettuna.
Tietokantataulun muokkaaminen
Valitettava totuus on se, että vaikka tekisimme kuinka hienon tietokantasuunnitelman, tulee se muuttumaan ajan myötä erilaisten asiakkailta ja muilta sidosryhmiltä tulevien toiveiden ja tarpeiden perusteella. Tietokantaa ei kannata luoda täysin uudestaan jokaisen muutoksen perusteella, vaan sitä voi muokata ALTER TABLE -lausekkeilla -- esimerkiksi uusien sarakkeiden lisääminen tauluun on melko suoraviivaista.
Tässä materiaalissa toistaiseksi käyttämämme tietokannanhallintajärjestelmä, SQLite, tukee vain muutamia muokkausoperaatiota. Näistä kannattaa varmaan tuntea ainakin ADD COLUMN, joka lisää tietokantatauluun uuden sarakkeen. Tämä tehdään SQLitessä seuraavasti:
ALTER TABLE Opiskelija ADD COLUMN kutsumanimi varchar(50);
ALTER TABLE -lausekkeiden kanssa voi käyttää myös rajoitteita suunnilleen vastaavasti kuten tietokantataulua luotaessa.
Muiden tietokannanhallintajärjestelmien tarjoamia monipuolisempia vaihtoehtoja voit nähdä esimerkiksi W3Schools-sivustolla -- lue nyt heidän ALTER TABLE -oppaansa.
Väliaikaisten näkymien luominen
Ohjelmia suunniteltaessa ja rakentessa ohjelmoija pilkkoo ohjelman toiminnallisuutta pienempiin osiin muunmuassa metodien ja luokkien avulla. Tietokantakyselyitä toteuttaessa ohjelmoija vastaavasti voi pilkkoa tehtäväänsä osiin väliaikaisten näkymien avulla. Väliaikaiset näkymät ovat tallennettuja SQL-kyselyitä, joiden suorituksesta saatuja tulostauluja voidaan käyttää osana muita kyselyitä.
Väliaikainen näkymä luodaan komennolla CREATE VIEW NäkymänNimi AS kysely, missä NäkymänNimi on nimi, jonka perusteella väliaikaiseen näkymään pääsee käsiksi, ja kysely on SELECT-kysely, jonka suoritus tuottaa näkymän.
Tutustutaan tähän pikaisesti. Luodaan ensin käyttöömme taulu Kurssi, jossa on kursseja.
Luodaan tämän jälkeen näkymä nimeltä Ohjelmointikurssit, missä on vain ohjelmoinnin perusteet ja ohjelmoinnin jatkokurssi.
Valitse nyt kaikki kurssit näkymästä Ohjelmointikurssit -- haku tapahtuu samalla tavalla kuin taulusta haettaessa.
Poista näkymä lopuksi komennolla DROP VIEW NäkymänNimi.
Viikko 3
Relaatiomalli
Kurssin alussa materiaali johdatteli lukijoita relaatiomalliin seuraavalla kuvauksella.
Relaatiomallille on myös hieman formaalimpi määritelmä, johon tutustutaan seuraavaksi. Noudatamme tässä Edgar Coddin vuonna 1970 julkaistun artikkelin "A Relational Model of Data for Large Shared Data Banks" esitysasua.
Relaatio
Olkoon S1, S2, ..., Sn arvojoukkoja, joiden sisältämät arvot eivät ole välttämättä täysin erillisiä. Relaatio R on joukko n alkion kokoisia monikkoja. Jokaisen relaatiossa R olevan monikon ensimmäisen arvon tulee kuulua joukkoon S1, toisen arvon kuulua joukkoon S2 jne.
Relaatio R on siis osajoukko joukkojen S1, S2, ..., Sn välisestä karteesisesta tulosta S1 ⨯ S2 ⨯ ... ⨯ Sn.
Relaatio esitetään tyypillisesti taulukkona, jolla on seuraavat ominaisuudet:
- Jokainen taulukon rivi kuvaa yhtä relaation R monikkoa.
- Taulukon rivien järjestyksellä ei ole väliä.
- Jokainen taulukon rivi on erilainen.
- Sarakkeiden järjestyksellä kuvaa relaation arvojoukkoja; ensimmäisen sarakkeen arvot tulevat arvojoukosta S1, toisen sarakkeen arvojoukosta S2 jne..
- Jokaiselle sarakkeelle annetaan annetaan nimi, joka kuvaa kunkin arvojoukon mahdollisia arvoja.
Pääavain, viittaaminen ja viiteavain
Jokaisella relaatiolla on tyypillisesti yksi arvojoukko tai arvojoukkojen yhdistelmä, joiden arvojen perusteella voidaan yksilöidä relaation monikko. Tällaista arvojoukkoa tai arvojoukkojen yhdistelmää kutsutaan pääavaimeksi. Oleellinen ominaisuus relaatioissa on myös saman tai toisen relaation arvoihin viittaaminen. Tämä tapahtuu viiteavaimen avulla. Relaatiossa R oleva arvojoukko tai arvojoukkojen yhdistelmä, joka ei ole relaation R pääavain, mutta sisältää jonkun relaation pääavaimia, on viiteavain.
Tietokannan normalisointi
Omenan (data) herkullisuudella, kuljetusvälineellä (tietokantasovellus ja palvelin), tai kaupassa tehtävällä asettelulla (sovelluksen käyttöliittymä) ei ole merkitystä jos omenoiden säilöntään (tietokantakaavio) ei ole kiinnitetty huomiota. -- Anonyymi
Tutustuimme aiemmin tietokannan suunnitteluun käsiteanalyysin kautta. Tutustutaan nyt täydentävään lähestymistapaan nimeltä tietokannan normalisointi (database normalization).
Tietokannan normalisointi on askeleittainen lähestymistapa tiedon jakamiseen loogisiksi tietokantatauluiksi ja niiden sarakkeiksi. Pääpiirteittäin lopputavoite on sama kuin käsiteanalyysissä -- jokaisen taulun pitäisi liittyä tiettyyn aiheeseen, ja tauluun määritellään vain sarakkeita jotka liittyvät samaan aiheeseen. Lähestymistapa on kuitenkin toisenlainen: tietokannan normalisoinnissa tutkimme tiedon välisiä riippuvuuksia ja suhteita, ja etsimme sieltä epäkohtia. Epäkohdat tyypillisesti jaetaan useampaan osaan, esimerkiksi tauluiksi.
Lähtökohtana tietokannan normalisoinnille ovat seuraavat relaatiomalliin liittyvät oletukset:
- Jokaisen tietokantataulun sarakkeen nimen tulee olla uniikki. Tietokantataulussa ei siis saa olla kahta saman nimistä saraketta.
- Jokaisen tietokantataulun sarakkeen tulee olla sellainen, että se sisältää korkeintaan yhden arvon. Yksittäisessä sarakkeen rivissä ei siis esimerkiksi saa säilöä listaa asioita.
- Jokaisen tietyssä tietokantataulun sarakkeessa olevan arvon tulee olla saman tyyppinen. Eri riveillä, mutta samassa sarakkeessa ei siis saa olla esimerkiksi kokonaislukutyyppisiä arvoja ja merkkijonotyyppisiä arvoja.
- Tietokantataulun sarakkeiden järjestyksen ei tule vaikuttaa tietoon. Sarakkeiden paikkaa tulee siis voida vaihtaa tarvittaessa.
- Tietokantataulussa ei tule olla kahta tai useampaa täsmälleen samat arvot sisältävää riviä. Jos rivi esiintyy kerran, ei sen toistamisesta ole hyötyä.
- Tietokantataulussa olevien rivien järjestyksellä ei tule olla merkitystä.
Tietokannan normalisointiin liittyy useampia tavoitteita; (1) tiedon kopioiden minimointi, (2) tiedon muuttamiseen liittyvien ongelmien vähentäminen, ja (3) tietokantaan tehtävien kyselyiden yksinkertaistaminen. Käytetään esimerkkinä seuraavaa yhden taulun avulla määriteltyä asiakastietokantaa, joka kertoo asiakkaan tiedot, laskutusosoitteen, ja kuljetusosoitteen.
![[Asiakas|(pk) asiakastunnus;etunimi;sukunimi;kayttajatunnus;ika;sukupuoli;yritys;puhelin_koti;puhelin_tyo;laskutusosoite_1;laskutusosoite_2;laskutusosoite_3;laskutus_kaupunki;laskutus_postinumero;kuljetusosoite_1;kuljetusosoite_2;kuljetusosoite_3;kuljetus_kaupunki;kuljetus_postinumero]](img/viikko5/normalisoitava.png)
Tietokannan suunnitteluun liittyy useampia normaalimuotoja, joista seuraavaksi tutustutaan muutamaan.
Ensimmäinen normaalimuoto
Ensimmäisessä normaalimuodossa olevien tietokantataulujen sarakkeiden arvot eivät saa olla listoja, eivätkä sarakkeet saa sisältää toistuvia ryhmiä. Jos tietokantataulun sarake olisi esimerkiksi "puhelinnumerot", mikä voisi sisältää useamman puhelinnumeron, tulisi se pilkkoa osiin, aivan kuten toistuvat arvot.
Edelläolevassa tietokantataulussa on toistuvia ryhmiä. Sekä puhelinnumero (kotipuhelin, työpuhelin) että osoite toistuu (kotiosoite, laskutusosoite). Emme tiedä sarakkeiden sisällöstä, joten emme tässä kohtaa osaa sanoa siitä, että onko sarakkeiden arvoissa jotain omituista -- jos tietokantataulussa olisi esimerkiksi sarakkeessa yritys useamman yrityksen nimi, tulisi se ottaa myös käsittelyyn.
Tietokannan saa ensimmäiseen normaalimuotoon eriyttämällä puhelinnumeron ja osoitteen omiksi tauluikseen, joista on viittaus Asiakas-tauluun. Uusissa tauluissa on myös sarake tyyppi, jonka avulla määritellään onko esimerkiksi puhelinnumero koti- vai työnumero.
![[Asiakas| (pk) asiakastunnus;etunimi;sukunimi;kayttajatunnus;ika;sukupuoli;yritys]
[Puhelin| (fk) asiakas:Asiakas; puhelin_tyyppi; numero]
[Osoite| (fk) asiakas:Asiakas; osoite_tyyppi; osoite_1; osoite_2; osoite_3; kaupunki; postinumero]
[Asiakas]1-*[Puhelin]
[Asiakas]1-*[Osoite]](img/viikko5/1nf.png)
Jos tietokantataulun sarakkeiden arvoissa olisi esimerkiksi listoja -- vaikkapa yksittäisen rivin yritys-sarakkeessa useampia yrityksiä, tulisi siitä myös tehdä erillinen taulu.
Toinen normaalimuoto
Ensimmäisessä normaalimuodossa kyse on ensiaskeleista tietokannan rakenteen järkevöittämiseen. Muissa normaalimuodoissa käsite funktionaalinen riippuvuus sarakkeiden välillä on oleellinen:
Tietokanta on toisessa normaalimuodossa jos (1) se on ensimmäisessä normaalimuodossa ja (2) tietokantataulun sarakkeet (poislukien avaimet) ovat funktionaalisesti riippuvaisia tietokantataulun pääavaimesta.
Jos tietokantataulun pääavain on määritelty yhden sarakkeen avulla, ovat kaikki sen sen sarakkeet automaattisesti funktionaalisesti riippuvaisia pääavaimesta. Käytännössä siis, jos taulu on ensimmäisessä normaalimuodossa ja sillä on yhden tai useamman sarakkeen kautta määritelty pääavain, on se automaattisesti toisessa normaalimuodossa.
Kolmas normaalimuoto
Tietokantataulu on kolmannessa normaalimuodossa jos (1) se on toisessa normaalimuodossa ja (2) siinä on vain sarakkeita, jotka eivät ole transitiivisesti riippuvaisia taulun pääavaimesta.
Kaikkien tietokantataulun sarakkeiden tulee olla itsenäisiä ja riippumattomia muista pääavaimeen kuulumattomista kentistä. Jos tietokantataulusta tunnistetaan sarakkeita, jotka ovat transitiivisesti riippuvaisia pääavaimesta, eriytetään ne omaksi taulukseen.
Esimerkiksi Osoite-taulussa oleva sarake kaupunki on transitiivisesti riippuvainen asiakkaasta postinumeron kautta. Voimme tällöin luoda uuden tietokantataulun Postinumero, joka sisältää jokaiseen postinumeroon liittyvät kaupungit.
Tietokantakyselyiden tekeminen ohjelmallisesti
Vaikka edelliset esimerkit tehtiin osana kurssimateriaalia, tehdään tietokantakyselyjä usein ohjelmallisesti tai suoraan tietokannanhallintajärjestelmässä, esimerkiksi konsolin kautta. Lähes jokainen ohjelmointikieli tarjoaa myös jonkinlaisen rajapinnan tietokantakyselyiden tekemiseen. Esimerkiksi Java-kielelle on määritelty yhtenäinen standardi tietokantakyselyiden tekemiseen, minkä avulla lähes sama koodi käy useamman tietokannan käyttöön.
Java ja JDBC
Java-kielessä on määritelty standardi (JDBC, Java Database Connectivity API) tietokantayhteyden luomiseen, tietoa hakevien kyselyjen muodolle, sekä tietoa muokkaavien kyselyjen muodolle. Jotta JDBCn avulla voidaan ottaa yhteys tietokantaan, tulee käytössä olla tietokannanhallintajärjestelmäkohtainen JDBC-ajuri, jonka vastuulla on tietokantayhteyden luomiseen liittyvät yksityiskohdat sekä kyselytulosten muuntaminen JDBC-standardin mukaiseen muotoon.
Oletetaan, että käytössämme on aiemmin näkemämme tietokantataulu Opiskelija:
Opiskelija
| opiskelijanumero | nimi | syntymävuosi | pääaine |
|---|---|---|---|
| 9999999 | Pihla | 1997 | Tietojenkäsittelytiede |
| 9999998 | Joni | 1993 | Tietojenkäsittelytiede |
| ... |
JDBCn avulla kyselyn tekeminen tietokantatauluun tapahtuu seuraavasti -- olettaen, että käytössämme on sekä tietokanta, että tietokannan ajuri:
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.ResultSet;
import java.sql.Statement;
public class Main {
public static void main(String[] args) throws Exception {
// luodaan yhteys jdbc:n yli sqlite-tietokantaan nimeltä "tietokanta.db"
Connection connection = DriverManager.getConnection("jdbc:sqlite:tietokanta.db");
// luodaan olio, jonka avulla voidaan tehdä kyselyitä tietokantaan
Statement statement = connection.createStatement();
// tehdään tietokantaan SQL-kysely "SELECT * FROM Opiskelija", jolla haetaan
// kaikki tiedot Opiskelija-taulusta -- tuloksena resultSet-olio
ResultSet resultSet = statement.executeQuery("SELECT * FROM Opiskelija");
// käydään tuloksena saadussa oliossa olevat rivit läpi -- next-komento hakee
// aina seuraavan rivin, ja palauttaa true jos rivi löytyi
while(resultSet.next()) {
// haetaan nykyiseltä riviltä opiskelijanumero int-muodossa
Integer opNro = resultSet.getInt("opiskelijanumero");
// haetaan nykyiseltä riviltä nimi String-muodossa
String nimi = resultSet.getString("nimi");
// haetaan nykyiseltä riviltä syntymävuosi int-muodossa
Integer syntVuosi = resultSet.getInt("syntymävuosi");
// haetaan nykyiseltä riviltä pääaine String-muodossa
String paaAine = resultSet.getString("pääaine");
// tulostetaan tiedot
System.out.println(opNro + "\t" + nimi + "\t" + syntVuosi + "\t" + paaAine);
}
// suljetaan lopulta yhteys tietokantaan
connection.close();
}
}
Ohjelman suoritus tuottaa (esimerkiksi) seuraavanlaisen tulostuksen:
999999 Pihla 1997 Tietojenkäsittelytiede 999998 Joni 1993 Tietojenkäsittelytiede 999997 Anna 1991 Matematiikka 999996 Krista 1990 Tietojenkäsittelytiede ...
Java-projekti ja JDBC-ajurin noutaminen
Jotta Javalla tehtävään projektiin saa tietokannan käyttöön, tulee ohjelmoijan noutaa tietokanta-ajuri. Ajurien noutaminen kannattaa hoitaa ns. riippuvuuksia hallinnoivan projektinhallintatyökalun, kuten Mavenin, avulla.
Oletamme tässä, että käytössäsi on NetBeans-ohjelmointiympäristö sekä Java 8. Huomaa, että tietojenkäsittelytieteen laitoksen NetBeans 8:aan on oletuksena määritelty käyttöön Java 7. Käynnistä laitoksen koneilla TMCBeans.
Maven-projektin luominen NetBeansissa
Uuden Mavenia käyttävän projektin luominen NetBeansissa tapahtuu valitsemalla File -> New Project -> Kategoriaksi Maven ja projektiksi Java Application. Tämän jälkeen valitaan Next, ja täytetään projektin tiedot. Alla on esimerkki projektin tiedoista, projektin sijainti (Project location) on konekohtainen.
Tämän jälkeen painetaan Finish, ja projekti ilmestyy NetBeansin vasemmassa laidassa olevalle listalle. Etsi nyt projektin Project Files sisältä pom.xml-tiedosto -- se näyttää esimerkiksi seuraavalta:
<?xml version="1.0" encoding="UTF-8"?>
<project>
<modelVersion>4.0.0</modelVersion>
<groupId>tikape</groupId>
<artifactId>tikape</artifactId>
<version>1.0-SNAPSHOT</version>
<packaging>jar</packaging>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<maven.compiler.source>1.7</maven.compiler.source>
<maven.compiler.target>1.7</maven.compiler.target>
</properties>
</project>
Koska käytössämme on Java 8, vaihdetaan sekä maven.compiler.source että maven.compiler.source -arvot muotoon 1.8.
<?xml version="1.0" encoding="UTF-8"?>
<project>
<modelVersion>4.0.0</modelVersion>
<groupId>tikape</groupId>
<artifactId>tikape</artifactId>
<version>1.0-SNAPSHOT</version>
<packaging>jar</packaging>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<maven.compiler.source>1.8</maven.compiler.source>
<maven.compiler.target>1.8</maven.compiler.target>
</properties>
</project>
SQLite-ajurin lisäämien Maven-projektin riippuvuuksiin
Lisätään riippuvuus (dependency) SQLite-ajuriin osaksi sovellusta.
<?xml version="1.0" encoding="UTF-8"?>
<project>
<modelVersion>4.0.0</modelVersion>
<groupId>tikape</groupId>
<artifactId>tikape</artifactId>
<version>1.0-SNAPSHOT</version>
<packaging>jar</packaging>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<maven.compiler.source>1.8</maven.compiler.source>
<maven.compiler.target>1.8</maven.compiler.target>
</properties>
<dependencies>
<dependency>
<groupId>org.xerial</groupId>
<artifactId>sqlite-jdbc</artifactId>
<version>3.8.11.2</version>
</dependency>
</dependencies>
</project>
Nyt kun NetBeans-projektista valitsee oikealla hiirennapilla Dependencies ja klikkaa Download Declared Dependencies, latautuu JDBC-ajuri projektin käyttöön.
Ensimmäinen tietokantaa käyttävä Maven-ohjelma
Avaa projektiin liittyvä Source Packages, ja klikkaa tikape-pakkausta oikealle hiirennapilla. Valitse tämän jälkeen New -> Java Class, jonka jälkeen avautuu valikko, missä voit antaa luokalle nimen. Anna luokan nimeksi Main.
Avaa tiedosto tuplaklikkaamalla sitä. Muokkaa tiedostoa vielä siten, että se on seuraavan näköinen:
package tikape;
public class Main {
public static void main(String[] args) throws Exception {
}
}
Lisää projektiin import-komento import java.sql.*;, joka hakee kaikki SQL-kyselyihin liittyvät Javan kirjastot.
package tikape;
import java.sql.*;
public class Main {
public static void main(String[] args) throws Exception {
}
}
Avataan seuraavaksi tietokantayhteys tietokantaan testi.db, ja tehdään siellä kysely "SELECT 1", jolla pyydetään tietokantaa palauttamaan luku 1 -- käytämme tätä yhteyden testaamiseksi. Jos yhteyden luominen onnistuu, tulostetaan "Hei tietokantamaailma!", muulloin "Yhteyden muodostaminen epäonnistui".
package tikape;
import java.sql.*;
public class Main {
public static void main(String[] args) throws Exception {
Connection connection = DriverManager.getConnection("jdbc:sqlite:testi.db");
Statement statement = connection.createStatement();
ResultSet resultSet = statement.executeQuery("SELECT 1");
if(resultSet.next()) {
System.out.println("Hei tietokantamaailma!");
} else {
System.out.println("Yhteyden muodostaminen epäonnistui.");
}
}
}
Hei tietokantamaailma!
Kun suoritamme ohjelman ensimmäistä kertaa valitsemalla Run -> Run Project, SQLite luo puuttuvan tietokannan paikalle uuden tietokannan. Projektin kansiossa on nyt tiedosto testi.db, joka on tietokantamme.
Tietokantakyselyiden tekeminen
Osoitteessa vuokraamo.db löytyy kuvitteellisen moottoripyörävuokraamon tietokanta. Lataa se edellä tehdyn projektin juureen ja kokeile kyselyn tekemistä kyseiseen tietokantaan.
Tietokannassa on tietokantataulu Pyora, jolla on sarakkeet rekisterinumero ja merkki. Jokaisen pyörän rekisterinumeron ja merkin tulostaminen tapahtuu seuraavasti -- huomaa myös, että olemme vaihtaneet käytössä olevaa tietokantaa.
Connection connection = DriverManager.getConnection("jdbc:sqlite:vuokraamo.db");
Statement stmt = connection.createStatement();
ResultSet rs = stmt.executeQuery("SELECT * FROM Pyora;");
while (rs.next()) {
String rekisterinumero = rs.getString("rekisterinumero");
String merkki = rs.getString("merkki");
System.out.println(rekisterinumero + " " + merkki);
}
stmt.close();
rs.close();
connection.close();
Käydään ylläoleva ohjelmakoodi läpi askeleittain.
Luomme ensin JDBC-yhteyden tietokantaan vuokraamo.db.
Connection connection = DriverManager.getConnection("jdbc:sqlite:vuokraamo.db");Kyselyn tekeminen tapahtuu pyytämällä yhteydeltä Statement-oliota, jota käytetään kyselyn tekemiseen ja tulosten pyytämiseen. Metodi executeQuery suorittaa parametrina annettavan SQL-kyselyn, ja palauttaa tulokset sisältävän ResultSet-olion.
Statement statement = connection.createStatement(); ResultSet resultSet = statement.executeQuery("SELECT * FROM Pyora;");Tämän jälkeen ResultSet-oliossa olevat tulokset käydään läpi. Metodia next() kutsumalla siirrytään kyselyn palauttamissa tulosriveissä eteenpäin. Kultakin riviltä voi kysyä sarakeotsikon perusteella solun arvoa. Esimerkiksi kutsu getString("rekisterinumero") palauttaa kyseisellä rivillä olevan sarakkeen "rekisterinumero" arvon String-tyyppisenä.
while(resultSet.next()) { String rekisterinumero = rs.getString("rekisterinumero"); String merkki = rs.getString("merkki"); System.out.println(rekisterinumero + " " + merkki); }Kun kyselyn vastauksena saadut rivit on käyty läpi, eikä niitä enää tarvita, vapautetaan niihin liittyvät resurssit.
stmt.close(); rs.close();
Lopulta tietokantayhteys suljetaan.
connection.close();
Päivityskyselyiden tekeminen
Kyselyt kuten rivien lisääminen ja poistaminen onnistuu myös ohjelmallisesti. Tällöin tuloksessa ei kuitenkaan ole erillistä ResultSet-oliota, vaan luku, joka kertoo kyselyn muuttaneiden rivien määrän. Allaoleva ohjelmakoodi lisää tietokantaan uuden pyörän.
Connection connection = DriverManager.getConnection("jdbc:sqlite:vuokraamo.db");
Statement stmt = connection.createStatement();
int changes = stmt.executeUpdate("INSERT INTO Pyora (rekisterinumero, merkki) VALUES ('RIP-34', 'Jopo');");
System.out.println("Kyselyn vaikuttamia rivejä: " + changes);
stmt.close();
connection.close();
Vastuiden eriyttäminen ja debug-viestien tulostaminen
Tietokantaa ohjelmallisesti käytettäessä kannattaa tietokantalogiikka ja sovelluslogiikka eriyttää toisistaan. Esimerkiksi tietokanta-ajurin hakeminen ja yhteyden luominen sopii hyvin erillisen tietokantaluokan vastuulle, ja sovelluskehittäjän työtä helpottaa, jos ohjelma mahdollistaa viestien tulostuksen. Samalla myös tietokannassa olevia käsitteitä on kätevä esittää luokkien avulla.
Pohditaan tätä seuraavaksi moottoripyörävuokraamoesimerkin ohjelmallisen käsittelyn kautta.
Koodissa on käsite, tehdään siitä olio (déjà-vu)
Moottoripyörävuokraamossa on pyöriä, joihin liittyy rekisterinumero ja merkki. Tehdään käsitteelle luokka Pyora, jolla on rekisterinumero ja merkki.
package tikape;
public class Pyora {
private String rekisterinumero;
private String merkki;
public Pyora(String rekisterinumero, String merkki) {
this.rekisterinumero = rekisterinumero;
this.merkki = merkki;
}
public String getRekisterinumero() {
return rekisterinumero;
}
public void setRekisterinumero(String rekisterinumero) {
this.rekisterinumero = rekisterinumero;
}
public String getMerkki() {
return merkki;
}
public void setMerkki(String merkki) {
this.merkki = merkki;
}
}
Luokasta Pyora voi tehdä uusia ilmentymiä konstruktorin avulla, joka saa ensimmäiseksi parametrikseen rekisterinumeron, ja toiseksi parametriksi merkin.
Pyora p = new Pyora("23-BC", "Royal Enfield");
System.out.println(p.getRekisterinumero());
System.out.println(p.getMerkki());
23-BC Royal Enfield
Luodaan olioita ResultSetissä olevista riveistä
Loimme juuri luokan kuvastamaan Pyora-tietokannan rivejä. Luodaan seuraavaksi ohjelmakoodi, joka lukee tietokannan ja muuntaa tietokannan rivit olioiksi.
Connection connection = DriverManager.getConnection("jdbc:sqlite:vuokraamo.db");
Statement stmt = connection.createStatement();
ResultSet rs = stmt.executeQuery("SELECT * FROM Pyora;");
List<Pyora> pyorat = new ArrayList<>();
while (rs.next()) {
String rekisterinumero = rs.getString("rekisterinumero");
String merkki = rs.getString("merkki");
pyorat.add(new Pyora(rekisterinumero, merkki));
}
stmt.close();
rs.close();
connection.close();
// pyorat-listalla on kaikki Pyora-tietokantataulun rivit pyora-olioina
Parameterisoidut kyselyt (Prepared Statement)
Tietokannan käyttämiseen tarkoitetut rajapinnat -- kuten tällä sivulla käytettävä sql.js -- tyypillisesti rajoittavat tietokantaan tehtäviä kyselyitä. Suoran kyselyn tekeminen muodossa DELETE FROM Opiskelija WHERE nimi = 'Gandhi' ei ole aina mahdollista, vaan kysely määritellään parametrin avulla -- esimerkiksi DELETE FROM Opiskelija WHERE nimi = ?, missä parametri annetaan kyselylle erikseen.
Prepared Statement-kyselyt ovat valmiiksi määriteltyjä kyselyitä, joissa kyselyissä käytettävät arvot annetaan parametreina. Valmiita kyselyitä käyttämällä estetään merkittävä osa SQL-injektioista, sillä parametreja käytettäessä varmistetaan että parametrien arvot käsitellään tiettyyn kenttään liittyvänä datana -- parametrit eivät siis "vuoda yli".
Valmiit kyselyt määritellään Connection-olion prepareStatement-metodin avulla. Metodi palauttaa PreparedStatement-olion, johon kyselyn käyttämät arvot määritellään parametreina. Esimerkiksi SQL-injektioesimerkissä oleva kysely luodaan valmiiden kyselyiden avulla seuraavasti:
// ...
String name = "nimi";
String password = "kala";
PreparedStatement statement =
connection.prepareStatement("SELECT * FROM User WHERE username = ? AND password = ?");
statement.setString(1, name);
statement.setString(2, password);
ResultSet resultSet = statement.executeQuery();
// ...
Vastaavasti tietokantaa muokkaavan kyselyn voi tehdä seuraavasti (alla oletetaan että taulussa User on vain kaksi saraketta):
// ...
String name = "nimi";
String password = "kala";
PreparedStatement statement =
connection.prepareStatement("INSERT INTO User VALUES (?, ?)");
statement.setString(1, name);
statement.setString(2, password);
statement.execute();
// ...
Prepared Statement-kyselyitä voi käyttää edellisessä luvussa toteutetun tietokanta-abstraktion kautta. Toteutetaan tällöin päivitys- ja kyselymetodit sellaisina, että niille annetaan kysely merkkijonona sekä ennalta määrittelemätön määrä parametreja, jotka lisätään kyselyyn kyselyä muodostettaessa.
public int update(String updateQuery, Object... params) throws SQLException {
PreparedStatement stmt = connection.prepareStatement(updateQuery);
for (int i = 0; i < params.length; i++) {
stmt.setObject(i + 1, params[i]);
}
int changes = stmt.executeUpdate();
if (debug) {
System.out.println("---");
System.out.println(updateQuery);
System.out.println("Changed rows: " + changes);
System.out.println("---");
}
stmt.close();
return changes;
}
Syötteen validointi
Käyttäjät voivat syöttää vahingossa (tai pahantahtoisesti) sovellukseen tietoa joka rikkoo sovelluksen toiminnan. Myös muilta sovelluksilta tuleva syöte saattaa olla vääränlaista. Ongelmien estämiseksi kaikki sovellukseen tuleva syöte on syytä validoida, eli tarkistaa että se on sellaista mitä sovellus odottaa.
Tietokantarajapinnassa tehtävien parameterisoitujen kyselyiden lisäksi sovelluksessa on siis syytä varmistaa mitään syötettä vastaanottaessa onko syöte sovelluksen odotuksia vastaavaa. Kurssiarvosanoja käsittelevässä sovelluksessa esimerkiksi kannattaa tarkistaa että syötetty arvosana on kokonaisluku sekä 0:n (hylätty) ja 5:n välillä. Tätä kutsutaan syötteen validoinniksi.
Tarkastettavia asioita:
- Puuttuuko vaadittu syöte
- Onko syötettä liikaa tai liian vähän
- Onko syöte oikean muotoista
- Jos syötteenä tulee numero, onko se liian suuri tai liian pieni
Validointiin läheisesti liittyvä käsite on datan varmentaminen (verification), eli sen tarkistaminen että syötetty data on oikein. Esimerkiksi sähköpostiosoitteiden tarkka validointi voi olla haastavaa. Tällöin on järkevämpää tehdä perusvalidointi, mutta jättää yksityiskohtien validointi pois ja sen sijaan varmistaa tiedon oikeellisuus vertaamalla sitä muuta kautta saatavaan tietoon, mikä sähköpostin tapauksessa varmaan tapahtuu helpoiten lähettämällä varmistussähköposti.
Viiteavainten käsittely ja koosteoliot
Aiemmat esimerkit ovat olleet melko yksinkertaisia, sillä niissä on ladattu tietoa yhdestä taulusta kerrallaan. Todellisuudessa tietokannoissa on usein viitteitä taulujen välillä, ja ohjelmallista tietokanta-abstraktiota käyttävän ohjelmoijan näkökulmasta olisi hyvin kätevää, jos nämä viitteet toimisivat myös olioina. Tutustutaan seuraavaksi viitteiden käsittelyyn taulujen välillä.
Oletamme, että tietokantakaaviomme on seuraavanlainen kuvitteellisen pyörävuokraamon tietokannan osa.
![[Pyora|(pk) rekisterinumero; merkki]
[Varaaja|(pk) asiakasnumero; etunimi; sukunimi]
[Varaus|(pk) varaustunnus; (fk) varaaja: Varaaja; (fk) pyora: Pyora; varaus_alkaa; varaus_loppuu]
[Pyora]1-*[Varaus]
[Varaus]*-1[Varaaja]](img/viikko4/vuokraamokaavio.png)
Kun ylläoleva tietokantakaavio luodaan Java-ohjelmakoodina siten, että taulujen väliset viitteet on otettu huomioon, luomme käytännössä kolme luokkaa: Pyora, Varaaja ja Varaus. Yhteen pyörään voi liittyä monta varausta, eli jokaiseen pyöräolioon liittyy lista varauksia. Vastaavasti, jokaiseen varaajaan voi liittyä monta varausta, eli jokaiseen varaajaolioon liittyy lista varauksia. Jokaiseen varausolioon liittyy yksi pyöräolio ja yksi varaajaolio.
import java.util.*;
public class Pyora {
private String rekisterinumero;
private String merkki;
private List<Varaus> varaukset;
// konstruktorit, getterit ja setterit
}
import java.util.*;
public class Varaaja {
private Integer asiakasnumero;
private String etunimi;
private String sukunimi;
private List<Varaus> varaukset;
// konstruktorit, getterit ja setterit
}
import java.util.*;
import java.sql.*;
public class Varaus {
private Integer varaustunnus;
private Pyora pyora;
private Varaaja varaaja;
private Timestamp varausAlkaa;
private Timestamp varausLoppuu;
// konstruktorit, getterit ja setterit
}
Luokassa Varaus käytetty muuttujan tyyppi Timestamp on eräs tietokannoissa käytetty muuttujatyyppi ajan tallentamiseen.
Ohjelmallisia tietokantakyselyitä suorittaessa -- esimerkiksi varauksen noutamisen yhteydessä -- tulee nyt hakea (1) varaustaulusta rivi, (2) haetun varausrivin pyora-kentästä löytyvällä viiteavaimella rivi pyörätaulusta, (3) haetun varausrivin varaaja-kentästä löytyvällä viiteavaimella rivi varaaja-taulusta, ja (4) luoda haettujen rivien perusteella oliot -- varaaja- ja pyörä-oliot tulee lisäksi asettaa varaukseen kuuluvaksi. Kokonaisuudessaan, ilman toiminnallisuuden jakamista erillisiin osiin, tietyn varauksen ja siihen liittyvän pyörän hakemiseen tarvittava kysely voisi olla vaikkapa seuraavanlainen.
String databaseAddress = "jdbc:sqlite:vuokraamo.db";
// haetaan tietokanta-ajuri ja avataan tietokantayhteys
Connection conn = DriverManager.getConnection(databaseAddress);
// haetaan yksittäinen varaus, jonka tunnus on 42
PreparedStatement stmt = conn.prepareStatement("SELECT * FROM Varaus WHERE varaustunnus = ?");
stmt.setObject(1, 42);
// suoritetaan kysely ja siirrytään ensimmäiseen vastausriviin
ResultSet rs = stmt.executeQuery();
rs.next();
// haetaan vastausriviltä oleelliset kentät
Integer varaustunnus = rs.getInt("varaustunnus");
Timestamp alku = rs.getTimestamp("varaus_alkaa");
Timestamp loppu = rs.getTimestamp("varaus_loppuu");
String pyora = rs.getString("pyora");
// luodaan varaus varaustunnuksen, sekä alun ja lopun perusteella
Varaus v = new Varaus(varaustunnus, alku, loppu);
// vapautetaan varaus-tauluun kohdistuneeseen kyselyyn liittyvät resurssin
rs.close();
stmt.close();
// haetaan yksittäinen pyörä, jonka rekisterinumero oli varaustaulusta haetussa rivissä
stmt = conn.prepareStatement("SELECT * FROM Pyora WHERE rekisterinumero = ?");
stmt.setObject(1, pyora);
// suoritetaan kysely ja siirrytään ensimmäiseen vastausriviin
rs = stmt.executeQuery();
rs.next();
// haetaan vastausriviltä oleelliset kentät
String rekisterinumero = rs.getString("rekisterinumero");
String merkki = rs.getString("merkki");
// luodaan pyörä vastauksen perusteella
Pyora p = new Pyora(rekisterinumero, merkki);
// asetetaan pyörä varaukseen liittyväksi pyöräksi
v.setPyora(p);
// vapautetaan kyselyyn liittyvät resurssit ja suljetaan tietokantayhteys
rs.close();
stmt.close();
conn.close();
// nyt käytössämme on varaus-olio, sekä varaukseen liittyvä pyörä-olio
Käytännössä toiminnallisuutta kuitenkin jaetaan osiin.
Data Access Object -suunnittelumalli
Tietokantasovelluksia toteuttaessa on hyvin tyypillistä abstrahoida, eli piilottaa, konkreettinen tiedon hakemis- ja tallennustoiminnallisuus siten, että ohjelmoijan ei tarvitse nähdä sitä jatkuvasti. Ideana on, että sovelluskehittäjä käyttää DAO-rajapinnan toteuttamia olioita, ja se, että mistä tai miten tiedot konkreettisesti haetaan ei ole sovelluksen muiden osien tiedossa.
Hahmotellaan hakemiseen ja poistamiseen liittyvää rajapintaa, joka tarjoaa metodit findOne, findAll ja delete, eli toiminnallisuudet hakemiseen ja poistamiseen. Tehdään rajapinnasta geneerinen, eli toteuttava luokka määrittelee palautettavien olioiden tyypin sekä avaimen.
import java.sql.*;
import java.util.*;
public interface Dao<T, K> {
T findOne(K key) throws SQLException;
List<T> findAll() throws SQLException;
void delete(K key) throws SQLException;
}
Metodi findOne hakee tietyllä avaimella haettavan olion, jonka tyyppi voi olla mikä tahansa. Alustava hahmotelma konkreettisesta varausten hakemiseen tarkoitetusta VarausDao-luokasta on seuraavanlainen.
import java.util.*;
import java.sql.*;
public class VarausDao implements Dao<Varaus, Integer> {
@Override
public Varaus findOne(Integer key) throws SQLException {
// ei toteutettu
return null;
}
@Override
public List<Varaus> findAll() throws SQLException {
// ei toteutettu
return null;
}
@Override
public void delete(Integer key) throws SQLException {
// ei toteutettu
}
}
Käytännössä tyyppiparametrit annetaan rajapinnan toteuttamisesta kertovan avainsanan implements-yhteyteen. Ylläolevassa esimerkissä haettavan olion tyyppi on Varaus, ja sen avain on tyyppiä Integer.
Koska varausten hakemiseen tarvitaan myös pyörien hakemista, hahmotellaan myös pyörien hakemiseen liittyvää toiminnallisuutta. Luokan rakenne on hyvin samankaltainen kuin edellä -- suurin ero liittyy käsiteltävään olioon sekä avaimen tyyppiin (VarausDao käsittelee olioita, joiden avain on Integer-tyyppinen, kun taas PyoraDao käsittelee olioita, joiden avain on String-tyyppinen.
import java.util.*;
import java.sql.*;
public class PyoraDao implements Dao<Pyora, String> {
@Override
public Pyora findOne(String key) throws SQLException {
// ei toteutettu
return null;
}
@Override
public List<Pyora> findAll() throws SQLException {
// ei toteutettu
return null;
}
@Override
public void delete(String key) throws SQLException {
// ei toteutettu
}
}
Jatketaan luokan PyoraDao-toteuttamista. Lisätään luokalle pääsy tietokanta-abstraktioon, jolta voi pyytää tietokantayhteyden, ja hahmotellaan yksittäisen pyörän hakemista aiemman ohjelmakoodin perusteella. Emme tässä esimerkissä lisää pyörään siihen liittyviä varauksia.
import java.util.*;
import java.sql.*;
public class PyoraDao implements Dao<Pyora, String> {
private Database database;
public PyoraDao(Database database) {
this.database = database;
}
@Override
public Pyora findOne(String key) throws SQLException {
Connection connection = database.getConnection();
PreparedStatement stmt = connection.prepareStatement("SELECT * FROM Pyora WHERE rekisterinumero = ?");
stmt.setObject(1, key);
ResultSet rs = stmt.executeQuery();
boolean hasOne = rs.next();
if (!hasOne) {
return null;
}
String rekisterinumero = rs.getString("rekisterinumero");
String merkki = rs.getString("merkki");
Pyora p = new Pyora(rekisterinumero, merkki);
rs.close();
stmt.close();
connection.close();
return p;
}
@Override
public List<Pyora> findAll() throws SQLException {
// ei toteutettu
return null;
}
@Override
public void delete(String key) throws SQLException {
// ei toteutettu
}
}
Luokka Database on esimerkiksi seuraavanlainen -- huomaa, että jaamme tietokantakyselyiden tekemisen vastuuta jokaiselle Dao-rajapinnan toteuttavalle luokalle erikseen -- kyselyt eivät siis ole enää Database-luokassa.
import java.sql.*;
public class Database {
private String databaseAddress;
public Database(String databaseAddress) throws ClassNotFoundException {
this.databaseAddress = databaseAddress;
}
public Connection getConnection() throws SQLException {
return DriverManager.getConnection(databaseAddress);
}
}
Hahmotellaan nyt yksittäisen varaus-olion hakemista. Toteutetaan luokka siten, että se saa konstruktorissaan sekä viitteen tietokanta-olioon, että viitteen pyörien hakemiseen tarkoitettuun Dao-rajapintaan.
import java.util.*;
import java.sql.*;
public class VarausDao implements Dao<Varaus, Integer> {
private Database database;
private Dao<Pyora, String> pyoraDao;
public VarausDao(Database database, Dao<Pyora, String> pyoraDao) {
this.database = database;
this.pyoraDao = pyoraDao;
}
@Override
public Varaus findOne(Integer key) throws SQLException {
Connection connection = database.getConnection();
PreparedStatement stmt = connection.prepareStatement("SELECT * FROM Varaus WHERE varaustunnus = ?");
stmt.setObject(1, key);
ResultSet rs = stmt.executeQuery();
boolean hasOne = rs.next();
if (!hasOne) {
return null;
}
Integer varaustunnus = rs.getInt("varaustunnus");
Timestamp alku = rs.getTimestamp("varaus_alkaa");
Timestamp loppu = rs.getTimestamp("varaus_loppuu");
Varaus v = new Varaus(varaustunnus, alku, loppu);
Integer varaaja = rs.getInt("varaaja");
String pyora = rs.getString("pyora");
rs.close();
stmt.close();
connection.close();
v.setPyora(this.pyoraDao.findOne(pyora));
return v;
}
@Override
public List<Varaus> findAll() throws SQLException {
// ei toteutettu
return null;
}
@Override
public void delete(Integer key) throws SQLException {
// ei toteutettu
}
}
Nyt yksittäisen varauksen hakemisen yhteydessä palautetaan sekä varaus, että siihen liittyvä pyörä. Rajapintaa käyttävän toteutuksen näkökulmasta tietokannan käyttäminen toimii seuraavasti:
Database database = new Database("jdbc:sqlite:vuokraamo.db");
PyoraDao pyoraDao = new PyoraDao(database);
VarausDao varausDao = new VarausDao(database, pyoraDao);
Varaus varaus = varausDao.findOne(4);
System.out.println(varaus.getPyora().getRekisterinumero()
+ " " + varaus.getVarausAlkaa()
+ " - " + varaus.getVarausLoppuu());
HAB-4 2015-07-17 16:00:00.0 - 2015-07-18 10:00:00.0
Kokoelmien hakeminen
Voisimme nyt jo toteuttaa kaikkien varausten hakemisen siten, että kävisimme jokaisen varaus-taulussa olevan varaustunnuksen läpi yksitellen, ja lisäisimme siihen halutun pyörän. Tämä ei kuitenkaan ole haluttua. Kaikkien varausten hakeminen kannattanee toteuttaa siten, että haemme ensin kaikki varaukset, jonka jälkeen haemme pyörät, jotka lisäämme varauksiin. Kaikkien pyörien hakeminen -- jos emme toteuta erikseen pyöriin liittyvien varausten listausta -- tapahtuu esimerkiksi seuraavasti.
@Override
public List<Pyora> findAll() throws SQLException {
Connection connection = database.getConnection();
PreparedStatement stmt = connection.prepareStatement("SELECT * FROM Pyora");
ResultSet rs = stmt.executeQuery();
List<Pyora> pyorat = new ArrayList<>();
while (rs.next()) {
String rekisterinumero = rs.getString("rekisterinumero");
String merkki = rs.getString("merkki");
pyorat.add(new Pyora(rekisterinumero, merkki));
}
rs.close();
stmt.close();
connection.close();
return pyorat;
}
Nyt pyörien liittäminen varauksiin onnistuu kahdella tietokantakyselyllä (1) haetaan kaikki varaukset ja (2) haetaan kaikki pyörät -- yhdistäminen tapahtuu ohjelmakoodissa esimerkiksi seuraavasti.
@Override
public List<Varaus> findAll() throws SQLException {
Connection connection = database.getConnection();
PreparedStatement stmt = connection.prepareStatement("SELECT * FROM Varaus");
ResultSet rs = stmt.executeQuery();
Map<String, List<Varaus>> varaustenPyorat = new HashMap<>();
List<Varaus> varaukset = new ArrayList<>();
while (rs.next()) {
Integer varaustunnus = rs.getInt("varaustunnus");
Timestamp alku = rs.getTimestamp("varaus_alkaa");
Timestamp loppu = rs.getTimestamp("varaus_loppuu");
Varaus v = new Varaus(varaustunnus, alku, loppu);
varaukset.add(v);
String pyora = rs.getString("pyora");
if(!varaustenPyorat.containsKey(pyora)) {
varaustenPyorat.put(pyora, new ArrayList<>());
}
varaustenPyorat.get(pyora).add(v);
}
rs.close();
stmt.close();
connection.close();
for (Pyora pyora : this.pyoraDao.findAll()) {
if(!varaustenPyorat.containsKey(pyora.getRekisterinumero())) {
continue;
}
for (Varaus varaus : varaustenPyorat.get(pyora.getRekisterinumero())) {
varaus.setPyora(pyora);
}
}
return varaukset;
}
Yllä haetaan ensin kaikki varaukset. Varausolioita luotaessa luodaan kirjanpito varauksiin liittyvien pyörien (viiteavain tauluun Pyörä) liittymisestä varausolioihin. Tämän jälkeen haetaan pyörät, ja lisätään ne varaukseen.
Osajoukon hakeminen
Edellisessä esimerkissä on kuitenkin hieman hölmöä se, että haemme kaikki viitatussa taulussa olevat rivit. Pyörien tapauksessa tämä voi olla hyväksyttävää, jos niitä on melko vähän, ja voimme olettaa, että lähes jokaista pyörää varataan. Toisaalta, jos vastaavaa toteutusta tehtäisiin varaajiin liittyen, ei jokaisen varaajan hakeminen olisi toivottua.
Lisätään Dao-rajapintaan metodi findAllIn(Collection<K> keys), joka hakee ne oliot, joiden avaimet ovat annetussa joukossa.
import java.sql.*;
import java.util.*;
public interface Dao<T, K> {
T findOne(K key) throws SQLException;
List<T> findAll() throws SQLException;
List<T> findAllIn(Collection<K> keys) throws SQLException;
void delete(K key) throws SQLException;
}
Nyt jokaista rajapinnan toteuttavaa luokkaa tulee muokata siten, että se toteuttaa uuden metodin. Lisätään metodin luokalle PyoraDao -- metodissa haetaan kaikki ne rivit, joiden alkiot ovat annetussa joukossa.
@Override
public List<Pyora> findAllIn(Collection<String> keys) throws SQLException {
if (keys.isEmpty()) {
return new ArrayList<>();
}
// Luodaan IN-kyselyä varten paikat, joihin arvot asetetaan --
// toistaiseksi IN-parametrille ei voi antaa suoraan kokoelmaa
StringBuilder muuttujat = new StringBuilder("?");
for (int i = 1; i < keys.size(); i++) {
muuttujat.append(", ?");
}
Connection connection = database.getConnection();
PreparedStatement stmt = connection.prepareStatement("SELECT * FROM Pyora WHERE rekisterinumero IN (" + muuttujat + ")");
int laskuri = 1;
for (String key : keys) {
stmt.setObject(laskuri, key);
laskuri++;
}
ResultSet rs = stmt.executeQuery();
List<Pyora> pyorat = new ArrayList<>();
while (rs.next()) {
String rekisterinumero = rs.getString("rekisterinumero");
String merkki = rs.getString("merkki");
pyorat.add(new Pyora(rekisterinumero, merkki));
}
return pyorat;
}
Nyt VarausDaon metodia voidaan muuttaa sopivasti, jolloin taulusta Pyora haetaan vain ne rivit, jotka liittyvät varauksiin.
@Override
public List<Varaus> findAll() throws SQLException {
Connection connection = database.getConnection();
PreparedStatement stmt = connection.prepareStatement("SELECT * FROM Varaus");
ResultSet rs = stmt.executeQuery();
Map<String, List<Varaus>> varaustenPyorat = new HashMap<>();
List<Varaus> varaukset = new ArrayList<>();
while (rs.next()) {
Integer varaustunnus = rs.getInt("varaustunnus");
Timestamp alku = rs.getTimestamp("varaus_alkaa");
Timestamp loppu = rs.getTimestamp("varaus_loppuu");
Varaus v = new Varaus(varaustunnus, alku, loppu);
varaukset.add(v);
String pyora = rs.getString("pyora");
if (!varaustenPyorat.containsKey(pyora)) {
varaustenPyorat.put(pyora, new ArrayList<>());
}
varaustenPyorat.get(pyora).add(v);
}
rs.close();
stmt.close();
connection.close();
for (Pyora pyora : this.pyoraDao.findAllIn(varaustenPyorat.keySet())) {
for (Varaus varaus : varaustenPyorat.get(pyora.getRekisterinumero())) {
varaus.setPyora(pyora);
}
}
return varaukset;
}
Valmiit kirjastot
Nykyään markkinoilla löytyy huomattava määrä valmiita kirjastoja, jotka tarjoavat Dao-toiminnallisuuksia. Yksi tällainen kirjasto on ORMLite, joka abstrahoi ja toteuttaa osan tietokantakyselyistä ohjelmoijan puolesta. ORMLite-kirjaston saa projektiin lisäämällä siihen liittyvän riippuvuuden Mavenin pom.xml-tiedostoon.
<dependency>
<groupId>com.j256.ormlite</groupId>
<artifactId>ormlite-jdbc</artifactId>
<version>4.48</version>
</dependency>
ORMLiteä käytettäessä tietokantatauluja kuvaaville luokille lisätään annotaatiot @DatabaseTable(tableName = "taulun nimi"), jonka lisäksi oliomuuttujille lisätään @DatabaseField-annotaatiot, joissa määritellään sarakkeen nimi, johon oliomuuttuja liittyy. Jos oliomuuttuja on taulun pääavain, lisätään sille erillinen määrittely (id=true) annotaatioon @DatabaseField: @DatabaseField(id = true, columnName = "sarakkeen nimi").
Käytännössä ORMLite osaa luoda olioita tietokannasta haettavista riveistä annotaatioiden perusteella. Jokaisessa tietokantataulua kuvaavassa tulee olla myös tyhjä konstruktori. Luokka Pyora ORMLite-annotaatioilla olisi esimerkiksi seuraavanlainen (tässä pyörään liittyviä varauksia ei ole otettu huomioon):
import com.j256.ormlite.field.DatabaseField;
import com.j256.ormlite.table.DatabaseTable;
@DatabaseTable(tableName = "Pyora")
public class Pyora {
@DatabaseField(id = true, columnName = "rekisterinumero")
private String rekisterinumero;
@DatabaseField(columnName = "merkki")
private String merkki;
// jokaisella tallennettavalla oliolle tulee olla parametriton konstruktori
public Pyora() {
}
public Pyora(String rekisterinumero, String merkki) {
this.rekisterinumero = rekisterinumero;
this.merkki = merkki;
}
// getterit ja setterit
}
Nyt kaikkien pyörien hakeminen tietokannasta onnistuu seuraavasti. Huom! Käytössä on ORMLiten tarjoama Dao-rajapinta -- emme siis kirjoita erikseen ohjelmakoodia kyselyiden tulosten muuttamiseksi olioiksi.
ConnectionSource connectionSource
= new JdbcConnectionSource("jdbc:sqlite:vuokraamo.db");
Dao<Pyora, String> pyoraDao
= DaoManager.createDao(connectionSource, Pyora.class);
List<Pyora> pyorat = pyoraDao.queryForAll();
for (Pyora pyora : pyorat) {
System.out.println(pyora.getMerkki() + " " + pyora.getRekisterinumero());
}
Käytännössä ORMLite lukee luokkaan määritellyt annotaatiot, ja tekee niiden perusteella käytettävät tietokantakyselyt, joita ohjelmoija käyttää ORMLiten toteuttaman Dao-rajapinnan kautta.
Viitteiden käsittely
Osoitteessa http://ormlite.com/javadoc/ormlite-core/doc-files/ormlite_2.html oleva ORMLiten "How to Use"-dokumentaatio sisältää neuvoja ORMLiten käyttöön. Lisätään seuraavaksi toiminnallisuus pyörien hakemiseen Varaus-luokan kautta. Annotaatioiden määrittely tapahtuu kuten Pyora-luokalle, mutta viittausta pyörään määriteltäessä annotaatiolle @DatabaseField tulee kertoa, että sarake viittaa toiseen tauluun, ja että viitatusta taulusta tulee hakea oliolle arvo. Tämä tapahtuu lisäämällä annotaatioon parametrit foreign = true ja foreignAutoRefresh = true. Tämän lisäksi, myös viitattuun tauluun tulee lisätä annotaatiot.
@DatabaseTable(tableName = "Varaus")
public class Varaus {
@DatabaseField(id = true)
private Integer varaustunnus;
@DatabaseField(columnName = "pyora", canBeNull = false, foreign = true, foreignAutoRefresh = true)
private Pyora pyora;
private Varaaja varaaja;
@DatabaseField(columnName = "varaus_alkaa")
private Timestamp varausAlkaa;
@DatabaseField(columnName = "varaus_loppuu")
private Timestamp varausLoppuu;
public Varaus() {
}
// konstruktorit, getterit, setterit
Ylläolevassa esimerkissä Varaus-luokka on määritelty siten, että se liittyy tietokantatauluun Varaus. Sillä on lisäksi kenttä pyora, joka viittaa tauluun, johon Pyora-luokka liittyy. Luokalle Varaaja ei ole määritelty toiminnallisuutta.
Varauksiin liittyvien pyörien tulostaminen onnistuu nyt seuraavasti:
ConnectionSource connectionSource
= new JdbcConnectionSource("jdbc:sqlite:vuokraamo.db");
Dao<Varaus, String> varausDao
= DaoManager.createDao(connectionSource, Varaus.class);
List<Varaus> varaukset = varausDao.queryForAll();
for (Varaus varaus : varaukset) {
System.out.println(varaus.getPyora().getRekisterinumero() + ", alkaa " + varaus.getVarausAlkaa());
}
Viikko 4
Tietokannat osana muita sovelluksia
Viimeisen 20 vuoden aikana selaimen -- ja nykyään kännykän -- kautta käytettävät sovellukset ovat kiihtyvää tahtia syrjäyttäneet perinteisiä työpöytäsovelluksia. Tietokannan käyttöön toisen sovelluksen osana liittyvät perusajatukset eivät kuitenkaan ole juurikaan muuttuneet. Työpöytäsovellusten aikana työpöytäsovellus käytti joko paikallisella koneella olevaa tietokannanhallintajärjestelmää, tai otti etäyhteyden toisella koneella käynnissä olevaan tietokannanhallintajärjestelmään. Selaimessa toimivia sovelluksia käytettäessä tietokannanhallintajärjestelmä toimii palvelinohjelmiston -- eli sovelluksen, johon selain ottaa yhteyttä -- kanssa samalla koneella, tai erillisellä koneella, johon palvelinohjelmisto ottaa yhteyden tarvittaessa.
Tutustutaan tässä kappaleessa tietokantaa käyttävän palvelinohjelmiston toimintaan, sekä toteutetaan sellainen itse.
Selaimen ja palvelimen välinen kommunikaatio
Selain kommunikoi palvelimen kanssa tekemällä pyyntöjä joihin palvelin vastaa. Selain tekee pyynnön esimerkiksi kun käyttäjä kirjoittaa osoitekenttään sivun osoitteen -- tietokantojen-perusteet.github.io -- ja painaa enter. Tällöin tehdään hakupyyntö (GET) osoitteessa tietokantojen-perusteet.github.io olevalle palvelimelle. Palvelin vastaanottaa pyynnön, käsittelee sen -- esimerkiksi hakee haluttavan dokumentin tiedostojärjestelmästä -- ja luo käyttäjälle näytettävän sivun. Sivu palautetaan vastauksena pyynnölle tekstimuodossa. Selain päättelee vastauksen sisällön perusteella miten sivu tulee näyttää käyttäjälle, luo sivun ulkoasun, ja näyttää sivun käyttäjälle.
Sivun näyttämisen yhteydessä selain hakee myös sisältöä, joihin sivu viittaa. Esimerkiksi jokainen tällä sivulla oleva kuva haetaan erikseen, aivan kuten erilaiset dynaamista toiminnallisuutta lisäävät Javascript -tiedostot sekä sivun ulkoasun tyylittelyyn liittyvät tyylitiedostot.
Käyttäjän näkökulmasta selain tekee käytännössä kahdenlaisia pyyntöjä. Hakupyynnöt (GET) liittyvät tietyssä osoitteessa olevan resurssin hakemiseen, kun taas lähestyspyynnöt (POST) liittyvät tiedon lähettämiseen tiettyyn osoitteeseen.
Tutustutaan tähän käytännössä Javalla toteutetun Spark-nimisen web-sovelluskehyksen avulla.
Spark ja ensimmäinen web-sovellus
Spark-sovelluskehyksen käyttöönotto toimii luvun 8.2 osassa "Maven-projektin luominen NetBeansissa" esitetyllä tavalla. Toisin kuin oppaassa, Maven-projektin riippuvuudeksi halutaan lisätä Spark. Tiedosto pom.xml näyttää lopuksi esimerkiksi seuraavalta:
<?xml version="1.0" encoding="UTF-8"?>
<project>
<modelVersion>4.0.0</modelVersion>
<groupId>tikape</groupId>
<artifactId>tikape-web-sample</artifactId>
<version>1.0-SNAPSHOT</version>
<packaging>jar</packaging>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<maven.compiler.source>1.8</maven.compiler.source>
<maven.compiler.target>1.8</maven.compiler.target>
</properties>
<dependencies>
<dependency>
<groupId>com.sparkjava</groupId>
<artifactId>spark-core</artifactId>
<version>2.3</version>
</dependency>
</dependencies>
</project>
Oleellista edellä on se, että Javan versioksi on määritelty 1.8, ja sparkin versioksi 2.3.
Nyt voimme luoda uuden pääohjelmaluokan (seuraa luvun 2.3 kohtaa "Ensimmäinen tietokantaa käyttävä Maven-ohjelma") pääohjelmaluokan luomiseksi. Lisätään Main.java-tiedostoon rivi import static spark.Spark.*;, jolloin käyttöömme tulee oleellisimmat Sparkin tarjoamat toiminnallisuudet. Kutsutaan tämän jälkeen Sparkin get-metodia, ja määritellään sen avulla osoite, jota palvelinohjelmistomme tulee kuuntelemaan, sekä teksti, joka palautetaan, kun selaimella tehdään pyyntö annettuun osoitteeseen.
package tikape;
import static spark.Spark.*;
public class Main {
public static void main(String[] args) {
get("/hei", (req, res) -> {
return "Hei maailma!";
});
}
}
Yllä olevassa esimerkissä palvelimelle määritellään osoite /hei. Jos selaimella tehdään osoitteeseen pyyntö, pyyntöön vastataan tekstillä Hei maailma!.
Jos ylläolevan sovelluksen käynnistää, Spark käynnistää web-palvelimen osoitteeseen http://localhost:4567, eli paikallisen koneen porttiin 4567. Palvelin on tämän jälkeen käynnissä, ja odottaa siihen tehtäviä pyyntöjä. Kun haemme web-selaimella sivua osoitteesta http://localhost:4567, palauttaa palvelin selaimelle tekstimuotoista tietoa, ja selain näyttää käyttäjälle seuraavanlaisen sivun:
Mutta! Kun teemme pyynnön osoitteeseen http://localhost:4567/hei, eli palvelinohjelmiston osoitteeseen /hei, saammekin vastaukseksi ohjelmakoodissa määrittelemämme Hei maailma!-tekstin.
Vapise, google.
Useamman osoitteen kuunteleminen
Spark-palvelimelle määritellään get-metodin avulla palvelimen kuuntelemia osoitteita. Metodikutsun yhteydessä määritellään myös palvelimen palauttama data. Palautettava data on tekstiä, mutta selain päättelee palautetun tekstin sisällön perusteella, mitä tekstille tulee tehdä. Alla olevassa ohjelmakoodissa määritellään kaksi osoitetta, joista palautetaan dataa. Toinen palauttaa aiemmin nähdyn tekstin Hei maailma!, ja toinen palauttaa HTML-elementin, jonka selain käsittelee ja näyttää. Koska elementin sisällä on linkki Youtube-videoon, aloittaa selain videon hakemisen Youtube-palvelusta.
package tikape;
import static spark.Spark.*;
public class Main {
public static void main(String[] args) {
get("/hei", (req, res) -> {
return "Hei maailma!";
});
get("/testi", (req, res) -> {
return "<iframe width=\"640\" height=\"420\" src=\"https://www.youtube.com/embed/dQw4w9WgXcQ?rel=0&autoplay=1\"></iframe>";
});
}
}
Tiedon lähettäminen palvelimelle
Tiedon lähettäminen (POST) palvelimelle tapahtuu HTML-sivuilla lomakkeen avulla.
Lomakkeen määrittely
Lomakkeelle (form) määritellään metodiksi (method) lähetys, eli POST, sekä osoite, johon lomakkeella oleva tieto tulee lähettää. Lomakkeen määrittely alkaa muodossa <form method="POST" action="/osoite">, missä /osoite on palvelimelle määritelty osoite. Tätä seuraa erilaiset lomakkeen kentät, esimerkiksi tekstikenttä (<input type="text" name="nimi"/>), johon syötettävälle arvolle tulee name-kentässä määritelty nimi. Lomakkeeseen tulee lisätä myös nappi (<input type="submit" value="Lähetä!"/>), jota painamalla lomake lähetetään. Lomake voi olla kokonaisuudessaan esimerkiksi seuraava:
<form method="POST" action="/opiskelijat"> Nimi:<br/> <input type="text" name="nimi"/><br/> <input type="submit" value="Lisää opiskelija"/> </form>
Yllä määritelty lomake näyttää selaimessa (esimerkiksi) seuraavalta:
Nappia painamalla lomakkeeseen kirjoitettu tieto yritetään lähettää osoitteessa http://tietokantojen-perusteet.github.io olevan palvelimen osoitteeseen /opiskelijat. Ei taida onnistua :).
Tiedon lähetyksen vastaanotto
Palvelimelle määritellään tietoa vastaanottava osoite metodilla post, jolle annetaan parametrina kuunneltava osoite, sekä koodi, joka suoritetaan kun osoitteeseen lähetetään tietoa. Pyynnön mukana lähetettävään tietoon -- esimerkiksi ylläolevalla lomakkeella voidaan lähettää nimi-niminen arvo palvelimelle -- pääsee käsiksi req-nimisen parametrin metodilla queryParams.
post("/opiskelijat", (req, res) -> {
String nimi = req.queryParams("nimi");
System.out.println("Vastaanotettiin " + nimi);
return "Kerrotaan siitä tiedon lähettäjälle: " + nimi;
});
Samaa osoitetta voi käsitellä sekä get, että post-metodilla. Palvelin voi siis palauttaa selaimen tekemiin hakupyyntöihin tiettyä dataa -- esimerkiksi vaikkapa lomakkeen -- ja käsitellä lähetetyn tiedon erikseen. Alla on määritelty kaksi /opiskelijat-osoitetta kuuntelevaa toiminnallisuutta. Toinen palauttaa lomakkeen, toinen taas palauttaa tekstin, jonka osana on lomakkeella lähetetty nimi.
package tikape;
import static spark.Spark.*;
public class Main {
public static void main(String[] args) {
get("/opiskelijat", (req, res) -> {
return "<form method=\"POST\" action=\"/opiskelijat\">\n"
+ "Nimi:<br/>\n"
+ "<input type=\"text\" name=\"nimi\"/><br/>\n"
+ "<input type=\"submit\" value=\"Lisää opiskelija\"/>\n"
+ "</form>";
});
post("/opiskelijat", (req, res) -> {
String nimi = req.queryParams("nimi");
return "Kerrotaan siitä tiedon lähettäjälle: " + nimi;
});
}
}
Kun palvelin käynnistetään ylläolevalla ohjelmalla, löytyy osoitteesta http://localhost:4567/opiskelijat seuraavanlainen sivu:
Täytetään lomake -- vaikkapa nimellä Edgar F. Codd.
Kun painamme nyt nappia Lisää opiskelija, tekstikentän sisältö lähetetään palvelimelle lomakkeen action-kentän määrittelemään osoitteeseen. Jos lomakkeessa määritelty metodiksi (method) post, tehdään lähetyspyyntö. Jos action kenttä on /opiskelijat ja metodi POST, lähetettävä tieto vastaanotetaan ja suoritetaan rivillä post("/opiskelijat", (req, res) -> { alkavalla ohjelmakoodilla. Aiemmin määritellyllä ohjelmalla käyttäjälle näytetään seuraavanlainen sivu:
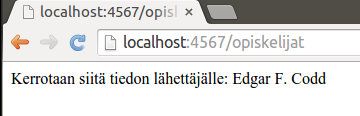
Tiedon säilöminen palvelimelle hetkellisesti
Voimme tallentaa vastaanotetun tiedon palvelimelle palvelimen käynnissäoloajaksi säilömällä sen esimerkiksi ArrayList-tyyppiseen listaan. Muokataan ylläolevaa aiempaa koodia siten, että hakupyyntö osoitteeseen /opiskelijat palauttaa sekä lomakkeen että tallennetut opiskelijat. Tämän lisäksi, lisätään osoitteeseen /opiskelijat tehtävän lähetyspyynnön käsittelyyn lomakkeelta saatavan nimi-kentän lisääminen ohjelmassa olevaan listaan.
package tikape;
import java.util.ArrayList;
import static spark.Spark.*;
public class Main {
public static void main(String[] args) {
ArrayList<String> nimet = new ArrayList<>();
get("/opiskelijat", (req, res) -> {
String opiskelijat = "";
for (String nimi : nimet) {
opiskelijat += nimi + "<br/>";
}
return opiskelijat
+ "<form method=\"POST\" action=\"/opiskelijat\">\n"
+ "Nimi:<br/>\n"
+ "<input type=\"text\" name=\"nimi\"/><br/>\n"
+ "<input type=\"submit\" value=\"Lisää opiskelija\"/>\n"
+ "</form>";
});
post("/opiskelijat", (req, res) -> {
String nimi = req.queryParams("nimi");
nimet.add(nimi);
return "Kerrotaan siitä tiedon lähettäjälle: " + nimi;
});
}
}
Nyt kun osoitteessa /opiskelijat olevalla lomakkeella tehdään useampia pyyntöjä, tulee lomakesivulle lisää näytettäviä opiskelijoita.
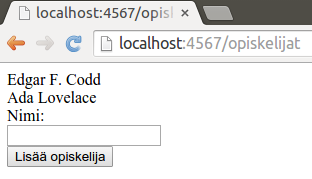
Tiedon esittäminen selaimessa
Selain näyttää käyttäjälle palvelimelta saamansa tekstimuotoisen vastauksen. Jos vastaus on HTML-muodossa, tulkitsee selain vastauksen, ja luo sen perusteella näkymän käyttäjälle. Toteutimme näkymän näyttämisen käyttäjälle aiemmin siten, että palautimme palvelimelta HTML-koodia.
return "<form method=\"POST\" action=\"/opiskelijat\">\n"
+ "Nimi:<br/>\n"
+ "<input type=\"text\" name=\"nimi\"/><br/>\n"
+ "<input type=\"submit\" value=\"Lisää opiskelija\"/>\n"
+ "</form>";
HTML-koodin palauttaminen suoraan palvelinohjelmistosta on kuitenkin hyvin epätyypillistä. Käytännössä html-sivut luodaan lähes aina ensin erilliseen tiedostoon, jonka palvelin palauttaa käyttäjälle. Voimme tehdä näin myös Sparkin kautta.
HTML-sivujen käyttöönotto projektissa
Lisätään projektiin riippuvuudeksi spark-template-thymeleaf-projekti, joka tuo käyttöön Thymeleaf-kirjaston. Projektin konfiguraatio on nyt kokonaisuudessaan seuraavanlainen:
<?xml version="1.0" encoding="UTF-8"?>
<project>
<modelVersion>4.0.0</modelVersion>
<groupId>tikape</groupId>
<artifactId>tikape-web-sample</artifactId>
<version>1.0-SNAPSHOT</version>
<packaging>jar</packaging>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<maven.compiler.source>1.8</maven.compiler.source>
<maven.compiler.target>1.8</maven.compiler.target>
</properties>
<dependencies>
<dependency>
<groupId>com.sparkjava</groupId>
<artifactId>spark-core</artifactId>
<version>2.3</version>
</dependency>
<dependency>
<groupId>com.sparkjava</groupId>
<artifactId>spark-template-thymeleaf</artifactId>
<version>2.3</version>
</dependency>
</dependencies>
</project>
Tehdään seuraavaksi resurssikansio (resources) projektin kansioon src/main/, jos sitä ei vielä ole. Uuden kansion saa luotua NetBeansin Files-välilehdellä klikkaamalla kansiota oikealla hiirennapilla, ja valitsemalla New -> Folder. Kun kansio on luotu, pitäisi käytössä olla kansio src/main/resources. Tämän jälkeen resources-kansioon tulee vielä luoda kansio templates, johon HTML-tiedostot tullaan laittamaan.
src allaolevassa kansiossa main on nyt kansio resources, jossa on taas kansio templates.Lisätään kansioon templates uusi html-dokumentti (New -> HTML File), ja asetetaan tiedoston nimeksi index.html.
src/main/resources/templates on tiedosto index.html.Käyttämämme Thymeleaf-kirjasto olettaa, että HTML-tiedostot ovat tietyn muotoisia -- palataan tähän myöhemmin. Tässä välissä riittää, että html-sivun sisällöksi kopioi seuraavan aloitussisällön.
<!DOCTYPE html SYSTEM "http://www.thymeleaf.org/dtd/xhtml1-strict-thymeleaf-4.dtd">
<html xmlns="http://www.w3.org/1999/xhtml" xmlns:th="http://www.thymeleaf.org">
<head>
<title>Otsikko</title>
<meta charset="utf-8" />
</head>
<body>
<h1>Hei maailma!</h1>
</body>
</html>
Huom! Jos näet virheen 500 Internal Server Error! sekä NetBeansin lokeihin tulee viestiä "Parse errorista", tarkista, että sivun sisältö on aluksi täsmälleen ylläoleva.
HTML-sivun palauttaminen käyttäjälle
Voimme palauttaa kansiossa src/main/java/resources/templates olevia .html-päätteisiä tiedostoja Sparkin avulla seuraavasti. Allaolevassa metodikutsussa määritellään kuunneltavaksi osoitteeksi /sivu, jonka jälkeen käyttäjälle palautetaan index-niminen sivu. Sivun nimen perusteella päätellään palautettava html-tiedosto -- nimi index muunnetaan muotoon src/main/java/resources/templates/index.html.
package tikape;
import java.util.HashMap;
import spark.ModelAndView;
import static spark.Spark.*;
import spark.template.thymeleaf.ThymeleafTemplateEngine;
public class Main {
public static void main(String[] args) {
get("/sivu", (req, res) -> {
HashMap map = new HashMap<>();
return new ModelAndView(map, "index");
}, new ThymeleafTemplateEngine());
}
}
Kun yllä määritelty sovellus käynnistetään, ja kansiossa src/main/java/resources/templates on tiedosto index.html, näytetään tiedoston sisältö käyttäjälle. Huomaathan, että tiedoston sisällön tulee olla kuten edellisessä kappaleessa näytetty. Näkymä on käyttäjälle esimerkiksi seuraavanlainen:
Palvelimelta saadun tiedon näyttäminen käyttäjälle
Thymeleaf-komponentin avulla voimme lisätä html-sivulle tietoa. Tämä tapahtuu lisäämällä HashMap-olioon put-metodilla arvo, esimerkiksi map.put("teksti", "Hei mualima!");.
get("/sivu", (req, res) -> {
HashMap map = new HashMap<>();
map.put("teksti", "Hei mualima!");
return new ModelAndView(map, "index");
}, new ThymeleafTemplateEngine());
Tämän jälkeen html-sivua index.html muokataan siten, että sinne lisätään "paikka" tiedolle. Tiedon lisääminen tapahtuu lisäämällä sivulle html-elementti, jossa on attribuutti th:text, jolle annetaan HashMap-olioon lisätyn arvon nimi aaltosulkujen sisällä siten, että aaltosulkuja edeltää dollarimerkki -- eli th:text="${teksti}". Elementti voi olla vaikka h2-elementti, jolloin kokonaisuus voisi olla vaikkapa seuraava <h2 th:text="${teksti}">testi</h2>.
<!DOCTYPE html SYSTEM "http://www.thymeleaf.org/dtd/xhtml1-strict-thymeleaf-4.dtd">
<html xmlns="http://www.w3.org/1999/xhtml" xmlns:th="http://www.thymeleaf.org">
<head>
<title>Otsikko</title>
<meta charset="utf-8" />
</head>
<body>
<h1>Hei maailma!</h1>
<h2 th:text="${teksti}">testi</h2>
</body>
</html>
Kun käynnistämme palvelimen, ja avaamme osoitteen http://localhost:4567/sivu, näemme seuraavanlaisen näkymän.
Listojen lisääminen sivulle
Tutustutaan vielä olioiden ja listojen käsittelyyn Thymeleafin avulla. Oletetaan, että käytössämme on seuraava Opiskelija-luokka.
package tikape;
public class Opiskelija {
private Integer id;
private String nimi;
public Opiskelija() {
}
public Opiskelija(Integer id, String nimi) {
this.id = id;
this.nimi = nimi;
}
public Integer getId() {
return id;
}
public void setId(Integer id) {
this.id = id;
}
public String getNimi() {
return nimi;
}
public void setNimi(String nimi) {
this.nimi = nimi;
}
}
Jokaisella opiskelijalla on siis tunnus sekä nimi. Tämän lisäksi, jokaiselle opiskelijalle kuuluu get- ja set-metodit, joiden avulla opiskelijaan liittyviä tietoja voidaan hakea ja muokata. Muokataan aiempaa ohjelmaamme siten, että käytössämme on listallinen opiskelijoita, jotka palautetaan sivun mukana thymeleafin käsiteltäväksi.
package tikape;
import java.util.ArrayList;
import java.util.HashMap;
import spark.ModelAndView;
import static spark.Spark.*;
import spark.template.thymeleaf.ThymeleafTemplateEngine;
public class Main {
public static void main(String[] args) {
ArrayList<Opiskelija> opiskelijat = new ArrayList<>();
opiskelijat.add(new Opiskelija(1, "Ada Lovelace"));
opiskelijat.add(new Opiskelija(2, "Charles Babbage"));
get("/opiskelijat", (req, res) -> {
HashMap map = new HashMap<>();
map.put("teksti", "Hei mualima!");
map.put("opiskelijat", opiskelijat);
return new ModelAndView(map, "index");
}, new ThymeleafTemplateEngine());
}
}
Lisätään vielä opiskelijat html-sivulle.
<!DOCTYPE html SYSTEM "http://www.thymeleaf.org/dtd/xhtml1-strict-thymeleaf-4.dtd">
<html xmlns="http://www.w3.org/1999/xhtml" xmlns:th="http://www.thymeleaf.org">
<head>
<title>Otsikko</title>
<meta charset="utf-8" />
</head>
<body>
<h1>Hei maailma!</h1>
<h2 th:text="${teksti}">testi</h2>
<h2 th:text="${opiskelijat}">opiskelijatesti</h2>
</body>
</html>
Kun nyt haemme sivua, saamme (esimerkiksi) seuraavanlaisen näkymän.
![Osoite http://localhost:4567/opiskelijat avattuna. Sivulla näkyy teksti Hei maailma!
Hei mualima!
[tikape.Opiskelija@4f4a43a5, tikape.Opiskelija@41ce9964]](img/viikko6/spark-index-opiskelijat.png)
Thymeleafin "for-each"-lause
Kurssilla ohjelmoinnin perusteet käytetään listan läpikäymiseen for-lausetta. Voisimme esimerkiksi tulostaa opiskelijoihin liittyvät tiedot seuraavasti Java-koodissa:
ArrayList<Opiskelija> opiskelijat = new ArrayList<>();
opiskelijat.add(new Opiskelija(1, "Ada Lovelace"));
opiskelijat.add(new Opiskelija(2, "Charles Babbage"));
for(Opiskelija opiskelija : opiskelijat) {
System.out.println("id: " + opiskelija.getId());
System.out.println("nimi: " + opiskelija.getNimi());
System.out.println();
}
id: 1 nimi: Ada Lovelace id: 2 nimi: Charles Babbage
Vastaavanlainen toiminnallisuus löytyy myös Thymeleafista. Voimme käydä listan elementit läpi attribuutilla th:each, jolle annetaan sekä läpikäytävän listan nimi -- taas aaltosulkujen sisällä siten, että aaltosulkuja ennen on dollarimerkki -- sekä yksittäisen listaelementin nimi, jota käytetään listaa läpikäydessä. Alla olevassa esimerkissä aloitetaan lista ul-elementin avulla. Jokaiselle opiskelijalle luodaan oma li-elementti (<li th:each="opiskelija: ${opiskelijat}">...</li>), jonka sisälle haetaan käsiteltävään opiskelijaan liittyvät tiedot.
<!DOCTYPE html SYSTEM "http://www.thymeleaf.org/dtd/xhtml1-strict-thymeleaf-4.dtd">
<html xmlns="http://www.w3.org/1999/xhtml" xmlns:th="http://www.thymeleaf.org">
<head>
<title>Otsikko</title>
<meta charset="utf-8" />
</head>
<body>
<h1>Hei maailma!</h1>
<h2 th:text="${teksti}">testi</h2>
<ul>
<li th:each="opiskelija: ${opiskelijat}">
<span th:text="${opiskelija.id}">1</span> <span th:text="${opiskelija.nimi}">Essi esimerkki</span>
</li>
</ul>
</body>
</html>
Kun sivua tarkastelee selaimesta, näyttää se seuraavalta:
Edelläolevassa esimerkissä käydään listalla olevat opiskelijat läpi, ja luodaan niiden perusteella sivulle dataa. Mielenkiintoista esimerkissä on se, että yksittäisen opiskelijan id-kenttään pääsee käsiksi sanomalla (esimerkiksi) <span th:text="${opiskelija.id}">1</span>. Tässä Thymeleaf päättelee opiskelija.id-kohdassa, että sen tulee etsiä opiskelija-oliolta getId()-metodia, kutsua sitä, ja asettaa tähän metodin palauttama arvo.
Tietokannan käyttöönotto
Tietokannan käyttöönotto onnistuu lukua 8 mukaillen. Tällä kertaa tosin hyödynnämme tietokantaa osana web-sovellusta. Opiskelijoiden noutaminen tietokannasta tapahtuisi esimerkiksi seuraavasti:
package tikape;
import java.util.HashMap;
import spark.ModelAndView;
import static spark.Spark.*;
import spark.template.thymeleaf.ThymeleafTemplateEngine;
import tikape.database.Database;
import tikape.database.OpiskelijaDao;
public class Main {
public static void main(String[] args) throws Exception {
Database database = new Database("jdbc:sqlite:opiskelijat.db");
database.setDebugMode(true);
OpiskelijaDao opiskelijaDao = new OpiskelijaDao(database);
get("/opiskelijat", (req, res) -> {
HashMap map = new HashMap<>();
map.put("opiskelijat", opiskelijaDao.findAll());
return new ModelAndView(map, "index");
}, new ThymeleafTemplateEngine());
}
}
Tietokantatransaktiot ja ACID
Pohjustusta
Tietokantatransaktioiden ymmärtämiseksi on hyvä hieman tuntea tietokannan toimintaa rautatasolla. Tietokanta käyttää kovalevyä/ssd-levyjä tiedon tallentamiseen, mutta rivien käsittely tapahtuu (keskus)muistissa. Kun riviä halutaan päivittää, se haetaan ensin kovalevyltä muistiin, päivitetään ja viedään takaisin levylle.
Keskusmuistin ongelma on se, että sen sisältö häviää esimerkiksi sähkökatkoksen sattuessa tai palvelimen kaatuessa. Havainnollistetaan ongelmallisuutta esimerkeillä:
- Annetaan kaikille yrityksen 1000000 kuukausipalkkaiselle työntekijälle 5% palkan korotus.
UPDATE Palkat SET kkpalkka = kkpalkka * 1,05Mitä jos tietokantapalvelin kaatuu, kun vasta 10000 muutettua riviä on tallennettu levylle? 990000 vihaista työntekijää jää ilman palkankorotusta? Tarvitaan jokin keino varmistaa, että päivitys tehdään kokonaan tai ei lainkaan. - Entä jos toinen prosessi lukee palkkatietoja juuri samalla kun niitä ollaan päivittämässä? Lukuoperaatio voi lukea esimerkiksi vain tietyn toimipaikan työntekijöiden palkat - 100 riviä. Jos päivitys on yhtäaikaa kesken, voi käydä niin, että osaan luetuista riveistä on ehditty jo tehdä päivitys ja osaan ei. Nyt osa työntekijöistä saa syyskuun palkkansa korotettuna ja osa ei? Tarvitaan jokin keino hallita yhtäaikaisia prosesseja.
Tietokantatransaktiot
Tietokantatransaktiot ratkaisevat edellä mainitut ongelmat. Ongelmat voidaan jakaa kahteen kategoriaan:
- Operaatioden keskeytymiset järjestelmän kaatuessa, häiriötilanteissa tai hallituissa keskeytyksissä
- Samanaikaset prosessit
Tietokantatransaktio sisältää yhden tai useamman tietokantaan kohdistuvan operaation, jotka suoritetaan (järjestyksessä) kokonaisuutena. Jos yksikin operaatio epäonnistuu, kaikki operaatiot perutaan, ja tietokanta palautetaan tilaan, missä se oli ennen transaktion aloitusta. Klassinen esimerkki tietokantatransaktiosta on tilisiirto, missä nostetaan rahaa yhdeltä tililtä, ja siirretään rahaa toiselle tilille. Jos tilisiirron suoritus ei onnistu -- esimerkiksi rahan lisääminen toiselle tilille epäonnistuu -- tulee myös rahan nostaminen toiselta tililtä perua.
Jokainen tietokantakysely suoritetaan omassa transaktiossaan, mutta, käyttäjä voi myös määritellä useamman kyselyn saman transaktion sisälle. Transaktio aloitetaan komennolla BEGIN TRANSACTION, jota seuraa kyselyt, ja lopulta komento COMMIT. Oletetaan, että käytössämme on taulu Tili(id, saldo).
CREATE TABLE Tili
(
id integer PRIMARY KEY,
saldo NOT NULL
)
Tilisiirto kahden tilin välillä toteutetaan yhtenä transaktiona seuraavasti.
BEGIN TRANSACTION; UPDATE Tili SET saldo = saldo - 10 WHERE id = 1; UPDATE Tili SET saldo = saldo + 10 WHERE id = 2; COMMIT;
Ylläolevassa transaktiossa suoritetaan kaksi kyselyä, mutta tietokannan näkökulmasta toiminto on atominen, eli sitä ei voi pilkkoa osiin. Komennon COMMIT yhteydessä muutokset joko tallennetaan kokonaisuudessaan tietokantaan, tai tietokantaan ei tehdä minkäänlaisia muutoksia.
Tietokantatransaktiota kirjoittaessa, ohjelmoija voi huomata tehneensä virheen. Tällöin suoritetaan komento ROLLBACK, joka peruu aloitetun transaktion aikana tehdyt muutokset. Suoritettua (COMMIT) tietokantatransaktiota ei voi perua.
Alla esimerkki kahdesta tietokantatransaktiosta. Ensimmäinen perutaan, sillä siinä yritettiin vahingossa siirtää rahaa väärälle tilille. Toinen suoritetaan. Kokonaisuudessaan allaolevan kyselyn lopputulos on se, että tililtä 1 on otettu 10 rahayksikköä, ja tilille 2 on lisätty 10 rahayksikköä.
BEGIN TRANSACTION; UPDATE Tili SET saldo = saldo - 10 WHERE id = 1; UPDATE Tili SET saldo = saldo + 10 WHERE id = 3; ROLLBACK; BEGIN TRANSACTION; UPDATE Tili SET saldo = saldo - 10 WHERE id = 1; UPDATE Tili SET saldo = saldo + 10 WHERE id = 2; COMMIT;
Jokainen tietokantakysely suoritetaan transaktion sisällä.
Tietokantatransaktiot ja rajoitteet
Koska tietokannanhallintajärjestelmä näkee transaktioiden sisällä suoritettavat käskyt atomisina, eli yksittäisenä kokonaisuutena, voivat tietokantatauluun määritellyt rajoitteet olla hetkellisesti rikki, kunhan ne transaktion suorituksen jälkeen ovat kunnossa.
Esimerkiksi suomen kirjanpitosääntöjen mukaan jokaisessa yrityksessä tulee olla kaksinkertainen kirjanpito. Tässä jokaisen tilitapahtuman yhteydessä tulee merkitä sekä mistä raha on otettu (debit), että mihin raha on laitettu (credit). Tällaisessa järjestelmässä tulee olla (esimerkiksi) tietokantataulu Kirjanpitotapahtuma, johon muutokset merkitään.
CREATE TABLE Kirjanpitotapahtuma
(
id integer PRIMARY KEY,
paivamaara date NOT NULL,
kirjanpitotili integer NOT NULL,
kuvaus text NOT NULL,
debit integer NOT NULL,
credit integer NOT NULL,
FOREIGN KEY(kirjanpitotili) REFERENCES Tili(id),
CONSTRAINT kirjaus_tasmaa CHECK (SUM(debit) = SUM(credit))
)
Nyt yhden transaktion sisällä voi tehdä useamman kirjanpitotapahtuman, kunhan transaktion suorituksen yhteydessä kirjanpitotapahtumien debit- ja credit-sarakkeiden summa täsmää.
ACID (Atomicity, Consistency, Isolation, Durability) on joukko tietokannanhallintajärjestelmän ominaisuuksia:
- Atomisuudella (
Atomicity) varmistetaan, että tietokantatransaktio suoritetaan joko kokonaisuudessaan tai ei lainkaan. Jos tietokannanhallintajärjestelmään tehtävät transaktiot eivät olisi atomisia, voisi esimerkiksi päivityskyselyistä päätyä tietokantaan asti vain osa -- tilisiirtoesimerkissä vain rahan ottaminen yhdeltä tililtä, mutta ei sen lisäämistä toiselle. - Eheydellä (
Consistency) varmistetaan, että tietokantaan määritellyt rajoitteet, kuten viiteavaimet, pätevät jokaisen transaktion jälkeen. Jos tietokanta ei mahdollistaisi eheystarkistusta, voisi esimerkiksi kirjanpito olla virheellinen. - Eristäytyneisyydellä (
Isolation) varmistetaan, että transaktio (A) ei voi lukea toisen transaktion (B) muokkaamaa tietoa ennenkuin toinen transaktio (B) on suoritettu loppuun. Tällä varmistetaan se, että jos transaktioita suoritetaan rinnakkaisesti, kumpikin näkee tietokannan eheässä tilassa. - Pysyvyydellä (
Durability) varmistetaan, että transaktion suorituksessa tapahtuvat muutokset ovat pysyviä. Kun käyttäjä lisää tietoa tietokantaan, tietokannanhallintajärjestelmän tulee varmistaa että tieto säilyy myös virhetilanteissa (jos transaktion suoritus onnistuu).
DBMS:t toteuttavat ACID-ominaisuudet käyttäen write-ahead-lokia (WAL). Se tarkoittaa sitä, että suoritettavaksi tuleva tietokantaoperaatio tallennetaan lokina levylle ennen rivien varsinaista päivitystä. Tällöin operaatiot voidaan suorittaa uudelleen, jos tietokantapalvelin kaatuu ennen kuin muistissa päivitetyt rivit ehditään tallentaa levylle. Tämä nopeuttaa tietokannan toimintaa merkittävästi, sillä pitkien operaatioden suorituksen valmistumista ei tarvitse odottaa ennen kuin sovellukselle voidaan vastata operaation onnistuneen. Kurssilla Transaktioiden hallinta tutustutaan tarkemmin transaktioiden toimintaan.
Viikko 5
NoSQL eli jotain muuta kuin relaatiomallia noudattavat tietokannat
Relaatiomalli ja SQL ovat hyvin ilmaisuvoimainen kombinaatio ja relaatiotietokannoilla pystytään ainakin teoriassa hoitamaan lähes kaikki mahdolliset tiedonhallintatarpeet. Relaatiotietokannat dominoivatkin tietokantaskeneä muutaman kymmenen vuoden ajan. 2000-luvulla alkoi kuitenkin nousta esiin uudentyyppisiä tietokantaratkaisuja, joita kuvaamaan lanseeratiin vuonna 2009 termi NoSQL.
Syitä uusien tietokantaratkaisujen syntyyn
Motivaatiota NoSQL-tietokantojen syntyyn oli muutamia. Ehkä tärkeimpänä tekijänä olivat massiivisen skaalan internetpalveluiden, esim. Amazonin ja Googlen käsittelemät tietomäärät, jotka edellyttävät tiedon hajautettua tallentamista ja käsittelyä. Relaatiomallia oli mahdotonta saada skaalautumaan palveluiden tarpeeseen ja monet yhtiöt kehittivät omia, aivan uudenlaisia tietokantaratkaisuja. Yhteistä näille oli se, että ne skaalautuivat hyvin, eli niiden suorituskyky oli mahdollista pitää riittävällä tasolla liittämällä tietokantaan uusia "koneita" kuormituksen kasvaessa, ja myös se, että toiminnallisuudeltaan ratkaisut olivat paljon rajoittuneempia kuin relaatiotietokannat.
Useimmat uudet tietokantaratkaisut tarjoavat paljon suppeamman kyselykielen kuin SQL ja ne eivät tue ACID-ominaisuuksia takaavia transaktioita. Hyvin tavanomaista uusissa tietokannoissa on se, että ne eivät yritäkään tarjota samanlaista ajantasaisuutta kuin relaatiotietokannat, eli sen sijaan, että kaikki kannan käyttäjät näkisivät tietokannan tilan koko ajan samanlaisena (ACID:in C eli consistency), on käytössä eventual consistency -malli, jossa periaatteena on, että jokainen tietokantaan tehty muutos näkyy kaikille käyttäjille ennemmin tai myöhemmin, mutta ei välttämättä heti, eli jonkun aikaa tilanne voi olla se, että tietokannan eri käyttäjät näkevät tietokannan tilan hieman erilaisena. Jos ajatellaan monia internetpalveluita täydellinen konsistenssi ei ole kaikkien operaatioiden suhteen välttämätöntä, ei esim. haittaa vaikka yksittäisen käyttäjän Facebook-päivitykset eivät ilmesty kaikille käyttäjolle aivan samalla hetkellä.
Toisena vahvana motivaationa uusien tietokantamallien kehittymiselle oli tarve joustavammille tavoille tallettaa erimuotoista dataa. Relaatiomalli nojaa vahvasti siihen että kannan skeema, eli taulut ja taulujen sarakkeet on ennalta määritelty. Jos syntyy usein tarve tallettaa uudenlaista dataa, esim. tauluihin tulee viikoittain uusia sarakkeita, tai jopa uudenlaisia tauluja, on relaatiomalli kankeahko. Toisaalta myös tarve tallettaa jokainen "asia" omaan tauluunsa tekee relaatiomallista kankean ja kyselyllisestikin raskaan tiettyihin käyttötarkoituksiin. Lääkkeenä näihin ongelmiin on syntynyt tietokantaratkaisuja, joissa datan skeema on huomattavasti löyhemmin määritelty kuin relaatiomallissa. Monissa uusissa tietokantatyypeissä data on tietokannan kannalta jopa täysin skeematonta, eli "tauluihin" voi tallettaa vapaamuotoista dataa, ja vastuu tiedon muodon oikeellisuudesta on siirretty täysin tietokannan käyttäjäjälle.
Erityyppiset NoSQL-tietokannat
Kaikki relaatiotietokannat ovat enemmän tai vähemmän samanlaisia ja tarjoavat standardoidun tavan eli SQL:n tietojen kyselyyn, ylläpitoon sekä tietokantaskeemojen muokkaukseen. NoSQL-tietokantojen kohdalla tilanne on täysin erilainen, ne ovat tiedon organisaatiotavoiltaan hyvinkin erilaisia ja mitään SQL:ää vastaavaa standardoitua kyselykieltä ei ole, kaikilla NoSQL-tietokannoilla on oma tapansa kyselyjen muodostamiseen.
NoSQL-tietokannat voidaan jakaa tiedon organisointitapansa perusteella neljään eri luokkaan:
- avain-arvotietokantoihin (engl. key value databases),
- dokumenttitietokantoihin (engl. document databases),
- saraketietokantoihin (engl. columnar databases) ja
- verkkotietokantoihin (engl. graph databases)
Tarkastellaan nyt erilaisia NoSQL-tietokantoja hieman tarkemmin.
Avain-arvotietokannat, Redis
Avain-arvotietokannat tarjoavat erittäin rajoitetun tietomallin. Kantaan talletetaan arvoja sekä arvon yksilöiviä avaimia. Tietokannan suhteen talletettavilla arvoilla ei ole (yleensä) mitään skeemaa eli rakennetta. Sovellusten on tulkittava kantaan talletettavat arvot haluamallaan tavalla esim. tietyn tyyppisenä oliona. Koska tietokanta on täysin skeematon, eivät avain-arvotietokannat tue viitteitä kantaan talletettujen arvojen välillä, eli mitään relaatiotietokantojen liitosta vastaavaa käsitettä ei avain-arvotietokannoilla ole.
Avain-arvotietokantojen tarjoamat kyselymahdollisuudet ovat erittäin rajoittuneet, yleensä on ainoastaan mahdollista hakea kannasta tiettyä avainta vastaava arvo.
Tarkastellaan nyt Redisiä joka on eräs suosituimmista avain-arvotietokannoista.
Redisin perusoperaatiot ovat set, get ja del joiden avulla käsitellään merkkijonomuotoisena talletettavia arvoja.
Seuraavassa esimerkissä käynnistetään Redis-konsoli, asetetaan arvo avaimille arto, aino ja olli. Haetaan kannasta muutamaa avainta vastaavia tietoja ja tuhotaan avaimeen arto liittyvä arvo.
melkki$ redis-cli 127.0.0.1:6379> set arto "olen arto 29 vuotta, yliopisto-opettaja" OK 127.0.0.1:6379> set aino "olen aino 21 vuotta, pajaohjaaja" OK 127.0.0.1:6379> set olli "olen olli 19 vuotta, fuksi" OK 127.0.0.1:6379> get pekka (nil) 127.0.0.1:6379> get arto "olen arto 29 vuotta, yliopisto-opettaja" 127.0.0.1:6379> del arto 127.0.0.1:6379> get arto (nil) 127.0.0.1:6379> get aino "olen aino 21 vuotta, pajaohjaaja" 127.0.0.1:6379>
Redis on siis erittäin yksinkertainen ja toimii oikeastaan hyvin samaan tapaan kuin Javan HashMap sillä erotuksella, että Redisiin ei voi helposti tallentaa normaaleja oliota, ja että Redisiin tallennetut arvot säilyvät vaikka ohjelma uudelleenkäynnistettäisiin.
Redis tajoaa tuen myös arvoille jotka ovat lukuja, joukkoja tai hashejä eli itsessään avain-arvo-pareja.
Mitä järkeä avain-arvotietokannoissa on? Ne vaikuttavat ominaisuuksiltaan erittäin rajoittuneilta ja relaatiotietokannoilla pystyy tekemään varmasti kaikki ne asiat, joihin avain-arvotietokannat pystyvät. Rajoituksistaan johtuen avain-arvotietokannat ovat kuitenkin suorituskyvyltään ja skaalautuvuudeltaan huomattavasti parempia kuin relaatiotietokanta, ja niiden avulla pystytään kuitenkin ratkaisemaan monia sovellusten käyttötarpeita. Viime aikoina on kuitenkin ollut nousussa trendi, jonka nimitys englanniksi on polyglot persistance, joka tarkoittaa suurinpiirtein sitä, että sovelluksessa on useita erityyppisiä tietokantoja ja kuhunkin käyttötarkoitukseen käytetään tarkoituksenmukaisinta ratkaisua.
Eräs hyvin yleinen käyttötarkoitus avain-arvotietokannoille on raskaiden operaatioiden tulosten väliaikainen talletus (engl. caching) mahdollisia uusia saman operaatioiden suorituksia varten.
Tarkastellaan tästä estimerkkinä internetistä Open Weather API:sta eri kaupunkien säätietoja hakevaa ohjelmaa. Ohjelma toiminta näyttää seuraavalta:
kaupunki: helsinki few clouds, temperature 15.770000000000039 celcisus kaupunki: turku Sky is Clear, temperature 16.0 celcisus kaupunki: vladivostok scattered clouds, temperature 11.360000000000014 celcisus kaupunki:
Jokaisen kaupungin kohdalla ohjelma hakee kaupungin säätiedot internetistä. Tiedon haku verkosta on kuitenkin hidas ja resurssien kulutuksen suhteen "kallis" operaatio (asialla voisi olla merkitystä jos ohjelmallamme olisi satoja tai tuhansia yhtäaikaisia käyttäjiä). Koska säätiedot pysyvät suunnilleen samana useiden minuuttien ajan, ohjelmaa voi optimoida siten, että kun käydään kerran hakemassa jonkun kaupungin säätiedot, talletetaan tieto joksikin aikaa Redisiin. Jos kaupungin säätä kysytään pian uudelleen, saadaan vastaus nopeasti ilman kallista internetoperaatiota. Noudatetaan siis näytettävien säätietojen suhteen eventual consistency -mallia.
Seuraavassa sääpalvelun toteuttavan luokan
import redis.clients.jedis.Jedis;
public class WeatherService {
private Jedis jedis;
public WeatherService() {
// luodaan yhteys paikallisen koneen Redisiin
jedis = new Jedis("localhost");
}
public void weatherOf(String city) throws Exception {
// kutsutaan metodia, joka hakee tiedot joko
// Redisistä tai internetistä
JsonElement weatherData = getDataFor(city);
// haetaan vastauksen sisältä oikeat osat
double temperature = getTemperatureFrom(weatherData);
String desc = getDescriptionFrom(weatherData);
System.out.println(desc + ", temperature "+temperature+ " celcisus");
}
// metodi joka hakee tiedot joko Redisistä tai internetistä
private JsonElement getDataFor(String city) throws Exception {
// etsitään kaupungin city säätietoja Redisistä
String weatherInfo = jedis.get(city);
// jos ei löytyny
if (weatherInfo==null) {
// haetaan tiedot internetistä
weatherInfo = readFromUrl("http://api.openweathermap.org/data/2.5/weather?q="+city);
// ja talletetaan ne Redisiin
jedis.set(city, weatherInfo);
// määritellään tallennusajaksi 10 minuuttia eli 600 sekuntia
jedis.expire(city, 600);
}
// palautetaan tuote oikein muotoiltuna
return new JsonParser().parse(weatherInfo);
}
// apumetodeja...
}
Palvelua käytetään seuraavasti:
WeatherService weather = new WeatherService();
weather.weatherFor("Helsinki");
Kun haemme ensimmäistä kertaa esim. Helsingin tietoja, etsitään niitä (metodissa getDataFor) ensin rediksestä:
// nyt city = "Helsinki" String weatherInfo = jedis.get(city);
tiedot eivät löydy, joten metodi palauttaa null. Tämän takia mennään if-haaraan, jossa tiedot haetaan apumetodin avulla internetistä. Haetut tiedot talletetaan ensin Redisiin:
// nyt city="Helsinki" ja weatherInfo Helsingin sään 'raakadata' jedis.set(city, weatherInfo);
talletetulle datalle asetetaan myös elinaika sekunteina:
jedis.expire(city, 600);
tämän jälkeet data palautetaan kutsujalle.
Jos Helsingin säätietoja haetaan 600 sekunnin sisällä uudelleen, löytyvät tiedot suoraan Redisistä. 600 sekunnin kuluttua hakuoperaatio jedis.get('Helsinki') palauttaa jälleen null ja tuore säätilanne haetaan internetistä.
Ohjelman koodi kokonaisuudessan löytyy GitHubista
Lista suosituimmista avain-arvotietokannoista.
Dokumenttitietokannat, MongoDB
Dokumenttitietokantojen voi ajatella sijoittuvan jonnekin relaatiotietokantojen ja avain-arvotietokantojen puolen välin tienoille. Dokumenttikannat perustuvat avain-arvotietokantojen tapaan arvojen tallettamiseen avaimen perusteella. Arvot tai dokumentit kuten niitä dokumenttikantojen kontekstissa nimitetään voivat kuitenkin olla itsessään hyvin monimutkaisia oliota, jotka sisältävät kenttiä, joiden arvona voi olla joko normaaleja arvoja kuten lukuja ja merkkijonoja tai muita olioita. Toisin kuin avain-arvotietokannoissa, dokumenttikannat "näkevät" tietokantaan talletettujen dokumenttien sisään, ja mahdollistavat talletettujen dokumenttien sisällön suhteen tehdyt kyselyt.
Käytetään seuraavassa esimerkkinä ylivoimaisesti suosituimman dokumenttitietokannan MongoDB:n merkintöjä.
Dokumenttikannoissa käytetään tiedon loogisena esitysmuotona yleensä JSON:ia. Seuraavassa kurssia Ohjelmoinnin perusteet esittävä JSON-dokumentti:
{
"id": ObjectId("10"),
"nimi": "Ohjelmoinnin perusteet",
"laajuus": 5,
"luennot": [ "Arto Vihavainen", "Matti Luukkainen" ]
}
JSON-dokumentti koostuu avain-arvo-pareista. Avainta vastaava arvo merkitään kaksoispisteellä erotettuna avaimen yhteyteen.
Kurssi-dokumentissa on siis neljä avain-arvo-paria. Voidaankin ajatella että kurssilla on neljä kenttää. Näistä kentistä erikoisasemassa on MongoDB:n dokumentille automaattisesti generoima avainkenttä id jonka arvo on tyypiltään ObjectId.
Poikkeavaa relaatiotietokantoihin nähden on se, että kentän arvona voi olla taulukko.
Seuraavassa on opiskelijaa kuvaava dokumentti:
{
"id" : ObjectId("59"),
"nimi" : "Pekka Mikkola",
"opiskelijanumero" : 14112345,
"osoite" : {
"katu" : "Tehtaankatu 10 B 1",
"postinumero" : "00120",
"postitoimipaikka" : "Helsinki"
}
}
Nyt kentän osoite arvona on olio, jolla on itsellään omat kenttänsä.
Dokumenttitietokannassa dokumentit on lajiteltu kokoelmiin (engl. collection). Kokoelman merkitys on suunnilleen sama kuin taulun relaatiotietokannassa. Yhdessä kokoelmassa olevien dokumenttien ei kuitenkaa tarvitse olla kentiltään samanlaisia. Kenttiä voi olla vaihteleva määrä ja saman nimiset kentät voivat sisältää eri dokumenteilla eri tyyppisen arvon. Kokoelmille ei määritellä dokumenttikannoissa minkäänlaista skeemaa, eli on täysin sovellusten vastuulla, että kantaan talletetaan järkevää dataa, ja että kannasta luettava data tutkitaan oikein.
Kuten edellä opiskelijan kohdalla näimme, on dokumenttikannoissa mahdollista sisällyttää olioita toistensa sisään. Tilanne olisi myös voitu mallintaa "relaatiomallin tapaan" siten, että osoitteita varten olisi oma kokoelmansa, ja yksittäinen osoite mallinnettaisiin omana dokumenttina:
{
"id" : ObjectId("123"),
"katu" : "Tehtaankatu 10 B 1",
"postinumero" : "00120",
"postitoimipaikka" : "Helsinki"
}
Opiskelijadokumentti sisältäisi nyt ainoastaan viitteen osoitedokumenttiin:
{
"id" : ObjectId("59"),
"nimi" : "Pekka Mikkola",
"opiskelijanumero" : 14112345,
"osoite" : ObjectId("123")
}
Toisin kuin relaatiotietokantojen tapauksessa, dokumenttikannat eivät tarjoa tietokannan tasolla tapahtuvia liitosoperaatiota, ja edellisen esimerkin tapauksessa sovelluksen olisi itse huolehdittava siitä, että opiskelijaa haettaessa haetaan myös opiskelijan osoite tietokannasta.
Vaikka operaatio ei olekaan dokumenttikannan tasolla tuettu, on olemassa monia kirjastoja (esim. Javalle Morphia), jotka toteuttavat ohjelmallisen liitosoperaation siten, että sovellusohjelman ei tarvitse siitä huolehtia.
Relaatiotietokannoissa kannan skeeman muodostaminen on sikäli helppoa, että jos pyritään normalisoituun ratkaisuun on useimmissa tilanteissa olemassa noin yksi "järkevä" ratkaisu, joka toimii lähes yhtä hyvin riippumatta siitä miten kantaa käytetään.
Dokumenttikantojen suhteen tilanne on toinen. Tarkastellaan esimerkiksi Kursseja ja Opiskelijoiden kurssisuorituksia. Relaatiotietokannassa tilanne olisi suoraviivainen, Suoritus olisi Kurssin ja Opiskelijan liitostaulu.
Eräs mahdollisuus olisi tehdä täsmälleen sama ratkaisu dokumenttikannassa.
Kokoelma Opiskelija:
[
{
"id": ObjectId("10"),
"nimi" : "Lea Kutvonen",
"opiskelijanumero" : 13457678
},
{
"id": ObjectId("11"),
"nimi" : "Pekka Mikkola",
"opiskelijanumero" : 14012345
}
]
Kokoelma kurssi:
[
{
"id": ObjectId("34"),
"nimi" : "Ohjelmoinnin perusteet",
"laajuus" : 5
},
{
"id": ObjectId("35"),
"nimi" : "Tietokone työvälineenä",
"laajuus" : 1
}
]
Suoritus olisi nyt "liitostaulumainen" kokoelma:
[
{
"id": 55
"kurssi_id" : ObjectId("34"),
"opiskelija_id" : ObjectId("10"),
"arvosana" : 4
},
{
"id": 56
"kurssi_id" : ObjectId("35"),
"opiskelija_id" : ObjectId("10"),
"arvosana" : 5
},
{
"id": 57
"kurssi_id" : ObjectId("35"),
"opiskelija_id" : ObjectId("11"),
"arvosana" : 2
}
]
Vaihtoehtoja on kuitenkin myös muita. Käyttötapauksista riippuen saattaisi olla edullista tallettaa tieto suorituksista ("liitosdokumentin" id) myös kurssin ja opiskelijan yhteyteen:
Kokoelma Opiskelija:
[
{
"id": ObjectId("10")
"nimi" : "Lea Kutvonen",
"opiskelijanumero" : 13457678,
"suoritukset" : [ ObjectId("55"), ObjectId("56") ]
},
{
"id": ObjectId("11")
"nimi" : "Pekka Mikkola",
"opiskelijanumero" : 14012345,
"suoritukset" : [ ObjectId("57") ]
}
]
Kokoelma kurssi:
[
{
"id": ObjectId("34")
"nimi" : "Ohjelmoinnin perusteet",
"laajuus" : 5,
"suorittajat" : [ObjectId("10")]
},
{
"id": ObjectId("35")
"nimi" : "Tietokone työvälineenä",
"laajuus" : 1,
"suorittajat" : [ObjectId("10"), ObjectId("11")]
}
]
Jossain tapauksessa paras ratkaisu olisi luopua liitoksena toimivista dokumenteista eli kokoelmasta suoritukset ja tallettaa suoritukset kokonaisuudessaan opiskelija-dokumentteihin:
[
{
"id": ObjectId("10")
"nimi" : "Lea Kutvonen",
"opiskelijanumero" : 13457678,
"suoritukset" : [
{
"id": 55
"kurssi_id" : ObjectId("34"),
"arvosana" : 4
},
{
"id": 56
"kurssi_id" : ObjectId("35"),
"arvosana" : 5
}
]
},
{
"id": ObjectId("11")
"nimi" : "Pekka Mikkola",
"opiskelijanumero" : 14012345,
"suoritukset" : [
{
"id": 57
"kurssi_id" : ObjectId("35"),
"arvosana" : 2
}
]
}
]
Tämä ratkaisu vaikeuttaisi kurssin suorittajien selvittämistä, joten joissain käyttötapauksissa saattaisi olla edullista sisällyttää suoritukset molempiin opiskelijoihin ja kurssiin.
Yhtä "oikeaa" vastausta miten sovelluksen data kannattaa mallintaa dokumenttikannan kokoelmiksi ja dokumenteiksi ei ole olemassa. Parhaaseen tapaan vaikuttaa suuresti se minkälainen käyttöprofiili rakennettavalla sovelluksella on: datamalli kannattaa valita siten, että se tekee yleisimpien operaatioiden suorituksen nopeaksi ja helpoksi.
Kuten jo totesimme, dokumenttikannat eivät tue liitosoperaatioita, ja kyselyt kohdistuvat aina vain yhteen kokoelmaan. Dokumenttikannoilla ei ole mitään standardoitua kyselykieltä, jokaisen kannan kyselykieli on täysin omanlaisensa. Esim. MongoDB:n kyselykieli ei muistuta kovinkaan läheisesti SQLää.
Dokumenttikannat eivät myöskään tue useamman kokoelman yhtäaikaista muuttamista transaktionaalisesti. Kaikki yhteen kokoelmaan suoritettavat tapahtumat tehdään kuitenkin aina transaktionaalisesti.
Lisää MongoDB:stä ja sen käytöstä eri ohjelmointikielistä käsin löydät esim. osoitteesta https://docs.mongodb.org/manual/
Lista suosituimmista dokumenttitietokannoista.
Saraketietokannat
Relaatiomalli sopii suhteellisen hyvin tilanteisiin, joissa tietoa käsitellään lyhyin, pääasiassa taulun yksittäisiin riveihin kohdistuvin operaatioin (englanniksi tälläisestä tiedonkäsittelystä käytetään nimitystä online transaction processing, OLTP). Näin tapahtuu esimerkiksi pankin asiakastietokannassa kun asiakkaat tekevät saldokyselyjä, nostavat rahaa tai tekevät tilisiirtoja.
Tietokantojen käyttö on aivan erilaista silloin kun tavoitteena on luoda raportteja tai analysoida dataa eri tavoin, esim. selvittää pankin asiakkaiden keskimääräinen saldo tietyllä aikavälillä. Tällöin kyselyt kohdistuvat lähes koko tauluun, mutta usein vain pieneen osaan taulun sarakkeissa (englanniksi tälläisestä tiedonkäsittelystä käytetään nimitystä online analytical processing, OLAP). Analyysitietokannoissa tilanne on usein se, että tieto ei ole normalisoidussa muodossa, yksittäiset taulut saattavat sisältää satojakin sarakkeita, mutta toisaalta läheskään kaikilla sarakkeilla ei ole kannassa arvoja. Näissä tilanteissa relaatiotietokantojen suorituskyky saattaa olla huono, ja saraketietokannat (engl. columnar databases) voivat tarjota huomattavasti paremman vaihtoehdon.
Tarkastellaan tilannetta esimerkin kautta. Oletetaan, että analyysiin käytettyyn tietokantaan on talletettu firman työntekijöitä:
EmpId Lastname Firstname Sex Salary YearsEmployed 10 Smith Joe M 40000 1 12 Jones Mary F 50000 6 11 Johnson Cathy F 44000 3 22 Jones Bob M 55000 9
Relaatiotietokannat tallettavat tiedon levylle riveittäin, eli taulu tallentuisi levylle seuraavasti:
10;Smith;Joe;M;40000;1;12;Jones;Mary;F;50000;6;11;Johnson;Cathy;F;44000;3;...
Jos nyt haluttaisiin selvittää yrityksessä vähintään 5 vuotta työskennelleiden keskipalkka, tehtäisiin kysely
SELECT AVG(Salary) FROM Employees WHERE YearsEmployed > 4
Tässä olisi relaatiotietokannan tapauksessa luettava taulun koko data levyltä siitä huolimatta, että kysely ei tarvitse kuin pientä osaa taulun datasta. Jos taulussa olisi satoja sarakkeita (mikä on varsin tyypillistä analytiikkatietokannoissa), olisi kyselyn tekeminen erittäin hidasta johtuen juuri tarpeettoman raskaasta, kaiken datan hakevasta levyoperaatiosta.
Saraketietokannoissa tiedot talletetaan sarakkeittain, karkeasti ottaen jokainen sarake tai usein yhdessä käytettyjen sarakkeiden ryhmä omaan tiedostoonsa. Edellinen tietokanta siis talletettaisiin kutakuinkin seuraavasti
EmpId: 10;12;11;22 Lastname:Smith;Jones;Johnson;Jones Firstname:Joe;Mary;Cathy;Bob Sex:M;F;F;M Salary:40000;50000;44000;55000 YearsEmployed:1;6;3;9
Tehtäessä sama kysely, riittäisi että levyltä luettaisiin ainoastaan kyselyn kannalta tarpeellisten sarakkeiden Salary ja YearsEmployed tieto. Jos sarakkeita olisi suuri määrä, ero riveittäin talletettuun tietokantaan olisi suorituskyvyn suhteen huomattava.
Vanhemmman sukupolven saraketietokannoissa data on organisoitu relaatiotietokantojen tapaan tauluihin ja dataa hallitaan SQL:llä. Vanhemman polven saraketietokantoja ei välttämättä edes luokitella NoSQL-kannoiksi. Uudemman polven saraketietokannat taas noudattavat enemmän yhden tai muutaman ison tai "leveän" taulun skeematonta mallia. Tauluissa on sarakkeita erittäin suuri määrä, mutta läheskään kaikilla sarakkeilla ei ole arvoa. Näiden esikuvana on Googlen vuodesta 2004 asti kehittämä BigTable. Uuden polven ratkaisut mahdollistavat massiivisten datamäärien rinnakkaiskäsittelyn.
Suosituimmat uuden sukupolven saraketietokannat.
Verkkotietokannat
Relaatiotietokannat ja esittelemämme NoSQL-kantatyypit keskittyvät dataentiteettien esittämiseen. Relaatiotietokannat esittävät entiteetit taulujen riveinä, esim. Henkilö-taulussa jokainen ihminen esitettään omana rivinään. Yhteydet ja suhteet eri entiteettien välillä esitetään epäsuorasti vierasavaimien ja liitostaulujen avulla. Itse yhteys, esim. missä henkilö Arto on töissä saadaan selville vasta kyselyn aikana tapahtuvan liitosoperaation avulla.
Joissain tilanteissa entiteettien suhteiden selvittäminen relaatiotietokannassa saattaa olla erittäin hankalaa. Oletetaan, että meillä on Henkilöitä kuvaava taulu:
CREATE TABLE Henkilo ( id integer not null PRIMARY KEY, nimi string not null )
sekä taulu, joka liittää vanhemmat ja lapset toisiinsa:
CREATE TABLE Vanhemmuus ( id integer not null PRIMARY KEY, lapsi_id integer, vanhempi_id integer, FOREIGN KEY (lapsi_id) references Henkilo(id), FOREIGN KEY (vanhempi_id) references Henkilo(id) )
Jos nyt haluaisimme selvittää henkilön "Arto Vihavainen" kaikki sukulaiset, huomaamme, että kyselyn tekeminen SQL:llä olisi erittäin hankalaa.
Tilanne mutkistuisi entisestään jos haluaisimme kuvata myös muunlaisia suhteita, esim. henkilöiden työsuhteita firmoihin, jäsenyyksiä yhdistyksiin, ystävyyttä, omistussuhteita erilaisiin asioihin sekä asioista tykkäämisiä ja vihaamisia. Yksi vaikeuttava tekijä olisi se, että kaikki erilaiset suhteet pitäisi mallintaa omina liitostauluinaan. Jos ohjelmassa käytettävät suhdetyypit lisääntyisivät, tulisi tietokantaskeemaan lisätä koko ajan uusia erityyppisiä liitostauluja. Myös kyselyt muuttuisivat koko ajan hankallimmaksi ja vaatisivat yhä monimutkaisempia, raskaita liitosoperaatioita. Esim. seuraavien asioiden selvittäminen olisi SQL:llä melko työlästä:
- Arton kaikkien esivanhempien työpaikat
- Kirjat joista Arton esivanhemmat pitivät
- Arton ystävistä ja ystävien ystävistä, ja näiden ystävistä jne kaikki ne, jotka ovat opiskelleet samassa paikassa kun Arto
Ratkaisun tämänkaltaisiin tilanteisiin tuovat verkkotietokannat, jotka mallintavat eksplisiittisesti sekä entiteetit eli esim. henkilöt ja niiden ominaisuudet että entiteettien väliset suhteet kuten sukulaisuuden henkilöiden välillä. Kuten nimestä voi päätellä, on verkkotietokannan pohjalla olevana tietorakenteena verkko (engl. graph), joka koostuu entiteettejä kuvaavista solmuista (engl. node) ja niiden välisiä suhteita kuvaavista kaarista (engl. edge). Sekä solmuilla, että kaarilla voi olla attribuutteja. Verkko, joka kuvaa yllä olevan esimerkin mallintamista verkkotietokannan solmuiksi ja kaariksi:

Verkkotietokannat tarjoavat kyselykielen, jonka avulla on helppo "navigoida" verkossa. Toisin kuin relaatiotietokannoissa, jotka edellyttävät yhteyden muodostamiseen laskennallisesti kallista join-operaatiota, yhteyksien navigointi verkkotietokannassa on nopeaa. Verkkotietokannoille ei ole olemassa yhtä vakiintunutta kyselykieltä. On kuitenkin tiettyjä kyselykieliä, kuten tämän hetken suosituimman verkkotietokannan Neo4J:n käyttämä Cypher, joita jotkut muutkin verkkotietokannat tukevat.
Seuraavassa muutama esimerkki ylläolevaan verkkotietokantaan kohdistetuista Cypherillä tehdyistä kyselyistä. Haetaan ensin Arton vanhemmat
MATCH ({ name:"Arto" }) -[:CHILD_OF]-> (parent)
RETURN parent
MATCH-määre hakee ensin solmun, jonka nimenä on Arto ja sen jälkeen seurataan kaarta :CHILD_OF pitkin solmun vanhempiin, jotka kysely palauttaa. Kysely siis palauttaa ne solmut parent joille pätee ehto: solmuun johtaa kaari CHILD_OF sellaisesta solmusta johon liittyy attribuutti nimi, jonka arvo on Arto.
Kirjat joista Arton esivanhemmat pitävät:
MATCH ({ name:"Arto" }) -[:CHILD_OF*1..]-> (relative) -[:LIKES]-> (book:Book)
RETURN book
Nyt kysely palauttaa sellaiset solmut book joille pätee:
- solmun tyyppi on Book
- solmuun on :LIKES-tyyppinen kaari jostain solmusta johon päästään Artosta yhtä tai useampaa :CHILD_OF kaarta pitkin kulkemalla
Arton ystävistä ja ystävien ystävistä, ja näiden ystävistä jne kaikki ne, jotka ovat opiskelleet samassa paikassa kun Arto:
MATCH (arto: { name:"Arto" }) -[:FRIENDS_WITH*1..]-> (friend) -[:STUDIED_IN]-> (school)
WHERE arto -[:STUDIED_IN]-> (school)
RETURN friend
Vielä yksi esimerkki. Miten löytäisimme lyhimmän ystävien ketjun, joka yhdistää Arton ja Barack Obaman?
MATCH (arto: { name:"Arto" }) (barack:{ name:"Barack Obama" })
p = shortestPath( (arto) -[:FRIEND*1..]-> (barack) )
RETURN p
Eli ensin etsitään solmut joiden nimenä on Arto ja Barack, ja sen jälkeen Neo4J:n valmis funktio shortestPath etsii lyhimmän polun solmujen välillä. Tämä kysely olisi todennäköisesti mahdoton tehdä SQL:llä tai ainakin äärimmäisen vaikea muotoilla ja todella hidas suorittaa. Verkkotietokannat sopivatkin erittäin hyvin muutamiin sellasiiin käyttöskenaarioihin, joissa muut tietokantatyypit ovat lähes käyttökelvottomia. Verkkotietokantojen käyttö onkin yleistynyt esim. sosiaalisen median sovelluksissa ja suosittelujärjestelmissä.
Suosituimmat verkkotietokannat.
NOSQL ja NewSQL
NoSQL-tietokannat löivät läpi suuren kohun saattamina ja erityisesti startupeissa oli muodikasta ottaa käyttöön helpommin suurille käyttäjämäärille skaalautuvia NoSQL-kantoja kuten MongoDB. Pikkuhiljaa kohu on laantunut, ja enenevissä määrin ollaan menossa jo aiemmin mainittuun polyglot persistancen nimellä kulkevaan suuntaan, eli valitaan oikea työkalu kuhunkin käyttötarkoitukseen, ja erittäin tyypillistä onkin että jo hieman suuremmissa sovelluksissa on käytössä dokumentti-, avain-arvo- ja relaatiotietokanta. Uusimpana kehityssuuntana on ollut myös se, että vanhat relaatiotietokannat ovat ottaneet vaikutteita muista tietokantatyypeistä. Esim. tämän hetken suosituin Open Source -relaatiotietokanta PostgeSQL sisältää paljon dokumenttitietokantoja vastaavaa toiminnallisuutta. Kehitystä on tapahtunut myös toiseen suuntaan, jotkut dokumenttitietokannat ovat mahdollistaneet SQL:n käytön kyselykielenä.
Kahtiajaon hieman liudennuttua termin NoSQL sijaan onkin alettu puhua Not Only SQL -tietokannoista, ja termi on muokkautunut muotoon NOSQL. Päätään nostaa esille myös vielä melko epämääräisesti määritelty termi NewSQL. Wikipedian mukaan NewSQL:llä tarkoittaa seuraavaa:
NewSQL is a class of modern relational database management systems that seek to provide the same scalable performance of NoSQL systems for online transaction processing (OLTP) read-write workloads while still maintaining the ACID guarantees of a traditional database system.
Although NewSQL systems vary greatly in their internal architectures, the two distinguishing features common amongst them is that they all support the relational data model and use SQL as their primary interface.
Eräs melko paljon huomiota saanut NewSQL-tietokanta on vuonna 2015 Applen ostama FoundationDB, joka sisäiseltä organisoinniltaan on avain-arvotietokanta ja tarjoaa perinteistä relaatiotietokantaa skaalautuvamman ratkaisun, mutta tarjoaa kyselykieleksi (myös) SQL:n ja ACID-ominaisuudet takaavat transaktiot eli käyttäytyy sovellusohjelmien kannalta kuten normaali relaatiotietokanta.
SQL-tietokannanhallintajärjestelmien eroista
Olemme tällä kurssilla tähän asti käyttäneet enimmäkseen SQLite-tietokannanhallintajärjestelmää. SQLiten käyttöä kurssilla helpottavina piirteinä ovat muun muassa käyttäjähallinnan puuttuminen ja tietokannan kokoaminen yhteen tiedostoon, joten opiskelijat ovat voineet itse ladata tiedoston ja käyttää tietokantaa välittömästi. Opetuskäyttö onkin mainittu yhtenä SQLitelle hyvin soveltuvana käyttökohteena SQLiten kotisivulla.
Kuten jo aiemmin tuli ilmi, eri SQL-toteutukset noudattelevat kielen standardia vaihtelevissa määrin, eivätkä aina toimi täysin samoin. SQLite tarjoaa jotain tietoa standardin noudattamisestaan, ja vielä selkeämpi tämän suhteen on Postgres. Toisaalta jotkut toiset tietokannanhallintajärjestelmät eivät juurikaan tuo esille missä määrin ne noudattavat standardia.
Toisin kuin SQLite, useat muut (SQL-)tietokannanhallintajärjestelmät on jaettu niin sanotun client-server -mallin mukaisesti erilliseen palvelinosaan, jossa varsinainen tietokanta on, ja asiakasosaan joka tarjoaa käyttöliittymän palvelinosan tarjoamaan tietokannan. Yksi tälläisistä tietokannanhallintajärjestelmistä on jo yllä mainittu PostgreSQL, joka tulee meille vastaan seuraavassa luvussa kun siirrämme sovellusta verkkoon.
Eroista huolimatta SQL-tietokannanhallintajärjestelmien SQL-toteutukset toimivat enimmäkseen toisiaan vastaavasti. Valitettavasti muutamatkin pienet erot saattavat aiheuttaa paljon vaivaa järjestelmästä toiseen siirryttäessä.
SQLite ja PostgreSQL
Siirryttäessä käyttämään SQLiten sijaan PostgreSQL-järjestelmää, joudumme mahdollisesti muokkaamaan käytettyjä SQL-kyselyitä. Varsinaisten erojen lisäksi Postgres on muutenkin tarkempi syntaksin noudattamisesta, eikä välttämättä hyväksy suunnilleen oikein muotoiltuja kyselyitä jotka SQLite saattaa joskus hyväksyä.
Ongelmatilanteissa voisi tarkistaa mm seuraavia asioita:
- SQL-kielelle varatut avainsanat eivät ole Postgresissa täysin samat kuin SQLitessa. (On syytä mm huomioida USER)
- Tarjolla olevat tietotyypit saattavat poiketa (Postgres, SQLite)
- Ajan käsittely saattaa olla hieman erilaista (Postgres, SQLite)
- Yksityiskohtana mainittakoon lisäksi Postgresin SERIAL, jonka tapaamme seuraavassa kappaleessa.
Sovelluksen siirtäminen verkkoon
Web-sovelluksemme on tähän mennessä toiminut paikallisella koneella, mikä on hieman tylsää, sillä sovellusta olisi kiva päästä näyttämään myös kavereille. Tutustutaan tässä Heroku-nimisen pilvipalvelun käyttöön, ja siirretään kehittämämme Web-sovellus verkkoon kaikkien nähtäväksi.
Tarvitset sovelluksen siirtoon (1) tunnuksen Heroku-palveluun sekä (2) Heroku Toolbeltin.
Sovelluksen siirtäminen verkkoon: alkutoimet
Herokuun siirrettävät sovellukset tarvitsevat muutamia muutoksia:
Procfile-tiedoston lisääminen. Sovelluksen juuripolkuun tulee lisätä tiedosto
Procfile, jonka sisällä on sovelluksen käynnistämisessä käytettävä komento.web: java -cp target/classes:target/dependency/* tikape.Main
Komennon osa
tikape.Mainkuvaa pääohjelmaluokkaa, jonka kautta sovellus tulee käynnistää. Jos pääohjelmaluokkasi on toisessa pakkauksessa (ei tikape) tai pääohjelmaluokan nimi on jotain muuta (ei Main), tulee tätä muokata. Heroku käyttää tätä komentoa sovelluksen käynnistykseen.Maven-liitännäiset ohjelman kääntöprosessin automatisointiin. Sovelluksen
pom.xml-tiedostoon tulee lisätä seuraavat rivit. Rivit lisätään esimerkiksi</properties>-rivin jälkeen.<build> <plugins> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-compiler-plugin</artifactId> <version>2.5.1</version> <configuration> <source>1.8</source> <target>1.8</target> <optimize>true</optimize> <debug>true</debug> </configuration> </plugin> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-dependency-plugin</artifactId> <version>2.4</version> <executions> <execution> <id>copy-dependencies</id> <phase>package</phase> <goals> <goal>copy-dependencies</goal> </goals> </execution> </executions> </plugin> </plugins> </build>Sovelluksen käynnistäminen Herokun määräämässä portissa. Jokainen web-sovellus käynnistettään tiettyyn porttiin, jonka se varaa käyttöönsä. Heroku pyörittää useampia sovelluksia samalla palvelinkoneella, joten sille pitää antaa mahdollisuus portin asetukseen.
Portin asetus tapahtuu ympäristömuuttujan avulla, jonka Heroku antaa sovellukselle sovellusta käynnistettäessä. Käytännössä pääohjelmaluokkaan, joka käynnistää web-palvelimen, tulee lisätä seuraavat rivit -- lisää ne main-metodin alkuun.
// asetetaan portti jos heroku antaa PORT-ympäristömuuttujan if (System.getenv("PORT") != null) { port(Integer.valueOf(System.getenv("PORT"))); }
Ylläolevien muutosten avulla sovelluksen siirtäminen verkkoon onnistuu.
Heroku toolbeltin asennus
Asenna heroku toolbelt. Ohjeita löytyy esimerkiksi osoitteessa https://devcenter.heroku.com/articles/heroku-command.
Jos sinulla ei ole koneeseen pääkäyttäjän oikeuksia (root), asennuksen pitäisi silti olla mahdollista jos koneelle on ennestään asennettu muutama Herokun vaatima ohjelmapaketti. Joudut kuitenkin tekemään asennuksen hieman toisin.
Sovelluksen luominen Herokuun
Sovelluksen luomiseen Herokuun tarvitaan kaksi askelta. Ensimmäisessä askeleessa luodaan projektista git-repositorio (tätä ei tarvitse tehdä jos sovellus on jo git-versionhallinnassa), jonka jälkeen luodaan herokuun sijainti johon sovellus kopioidaan.
Projekti git-repositorioksi -- projektin luominen git-repositorioksi tapahtuu ajamalla komento
git initprojektin juurikansiossa (kansio, jossa löytyy tiedostopom.xml). Jos sovellus on jo esimerkiksi githubissa, ei tätä tarvitse tehdä.Heroku-projektin luominen -- suorita juurikansiossa komento
heroku create. Tämä luo sovellukselle sijainnin herokuun, johon sovelluksen voi lähettää.
Mahdollisissa ongelmatilanteissa kannattaa ensimmäiseksi katsoa mitä viestejä Herokun lokitiedostoon on päätynyt.
Tietokantaa käyttämättömän sovelluksen lähetys Herokuun
Sovelluksen lähetys herokuun sisältää tyypillisesti neljä askelta. Ensin poistamme turhat käännetyt lähdekooditiedostot, jotta ne eivät häiritse herokun toimintaa. Tämän jälkeen lisäämme tiedostot versionhallintaan, sitoudumme niiden lähettämiseen, ja siirrämme ne herokuun.
Turhien lähdekooditiedostojen poistaminen -- suorita projektin juurikansiossa komento
mvn clean, joka poistaa projektista käännetyt lähdekooditiedostot (kansio target).Tiedostojen lisääminen versionhallintaan -- suorita projektin juurikansiossa komento
git add ., joka lisää kaikki projektin tiedostot versionhallintaan.Tiedostojen lähettämiseen sitoutuminen -- suorita projektin juurikansiossa komento
git commit -m "viesti", joka sitouttaa lähetykseen juuri lisätyt tiedostot.Tiedostojen siirtäminen herokuun -- suorita projektin juurikansiossa komento
git push heroku master, joka lähettää tiedostot herokuun.
Nyt sovelluksesi on Herokussa.
Tietokannan riippuvuudet
Sovellukseen lisätään pääsy kahteen tietokantaan. Yksi on paikallisessa testauksessa ja kehitystyössä käyttämämme SQLite, ja toinen on Herokun käyttämä PostgreSQL. Niiden käyttämiseen tarvitaan JDBC-ajurit, jotka tulee lisätä sovelluksen pom.xml-tiedostoon.
<dependency>
<groupId>org.xerial</groupId>
<artifactId>sqlite-jdbc</artifactId>
<version>3.8.11.2</version>
</dependency>
<dependency>
<groupId>org.postgresql</groupId>
<artifactId>postgresql</artifactId>
<version>9.4-1201-jdbc4</version>
</dependency>
Tietokannan osoitteen lukeminen ja käyttö Herokussa
Heroku tarjoaa sovelluksen portin lisäksi myös JDBC-osoitteen ympäristömuuttujana. Kun luomme käyttöömme Database-oliota sovelluksen alussa, tulee tietokantaosoite valita sen mukaan, että onko ympäristömuuttujaa olemassa.
// käytetään oletuksena paikallista sqlite-tietokantaa
String jdbcOsoite = "jdbc:sqlite:kanta.db";
// jos heroku antaa käyttöömme tietokantaosoitteen, otetaan se käyttöön
if (System.getenv("DATABASE_URL") != null) {
jdbcOsoite = System.getenv("DATABASE_URL");
}
Database db = new Database(jdbcOsoite);
Nyt käytössämme on tietokantaosoite. Paikallisella koneella voimme jatkossakin käyttää SQLite-tietokantamoottoria, mutta Herokussa käytämme herokun määräämää tietokannanhallintajärjestelmää.
Tietokannan luominen sijaintikohtaisesti
Muokataan tämän jälkeen Database-luokkaa siten, että se sisältää tietokantataulujen luomiseen tarvittavat komennot, jotka suoritetaan sovelluksen käynnistyessä. PostgreSQL-komennot poikkeavat hieman SQLitestä, joten tehdään nämä erillisinä. Tiedämme, että käytössä on PostgreSQL-tietokanta, jos tietokannan osoitteessa on sana "postgre".
Alla on kuvattuna tietokantaluokan toiminnallisuus, joka toimii sekä Herokussa että paikallisesti. Luokassa luodaan tasan yksi tietokantataulu.
package tikape.db;
import java.sql.*;
import java.util.*;
import java.net.*;
public class Database {
private String databaseAddress;
public Database(String databaseAddress) throws Exception {
this.databaseAddress = databaseAddress;
init();
}
private void init() {
List<String> lauseet = null;
if (this.databaseAddress.contains("postgres")) {
lauseet = postgreLauseet();
} else {
lauseet = sqliteLauseet();
}
// "try with resources" sulkee resurssin automaattisesti lopuksi
try (Connection conn = getConnection()) {
Statement st = conn.createStatement();
// suoritetaan komennot
for (String lause : lauseet) {
System.out.println("Running command >> " + lause);
st.executeUpdate(lause);
}
} catch (Throwable t) {
// jos tietokantataulu on jo olemassa, ei komentoja suoriteta
System.out.println("Error >> " + t.getMessage());
}
}
public Connection getConnection() throws SQLException {
if (this.databaseAddress.contains("postgres")) {
try {
URI dbUri = new URI(databaseAddress);
String username = dbUri.getUserInfo().split(":")[0];
String password = dbUri.getUserInfo().split(":")[1];
String dbUrl = "jdbc:postgresql://" + dbUri.getHost() + ':' + dbUri.getPort() + dbUri.getPath();
return DriverManager.getConnection(dbUrl, username, password);
} catch (Throwable t) {
System.out.println("Error: " + t.getMessage());
t.printStackTrace();
}
}
return DriverManager.getConnection(databaseAddress);
}
private List<String> postgreLauseet() {
ArrayList<String> lista = new ArrayList<>();
// tietokantataulujen luomiseen tarvittavat komennot suoritusjärjestyksessä
lista.add("DROP TABLE Tuote;");
// heroku käyttää SERIAL-avainsanaa uuden tunnuksen automaattiseen luomiseen
lista.add("CREATE TABLE Tuote (id SERIAL PRIMARY KEY, nimi varchar(255));");
lista.add("INSERT INTO Tuote (nimi) VALUES ('postgresql-tuote');");
return lista;
}
private List<String> sqliteLauseet() {
ArrayList<String> lista = new ArrayList<>();
// tietokantataulujen luomiseen tarvittavat komennot suoritusjärjestyksessä
lista.add("CREATE TABLE Tuote (id integer PRIMARY KEY, nimi varchar(255));");
lista.add("INSERT INTO Tuote (nimi) VALUES ('sqlite-tuote');");
return lista;
}
}
Ylläolevassa esimerkissä tarjotaan yhteyden muodostaminen joko PostgreSQL-tietokantaan tai SQLite-tietokantaan riippuen yhteydestä. Tämän lisäksi komento yrittää myös luoda tietokantataulua -- sekä PostgreSQL:n tapauksessa myös poistaa sen. Metodeja postgreLauseet ja sqliteLauseet kannattanee muokata omaan tarkoitukseen sopivaksi.
Tietokanta osana DAO-toiminnallisuutta
Nyt tietokannan voi ottaa osaksi tietokantaa abstrahoivaa Dao-luokkaa.
// pakkausmäärittely ja importit
import java.sql.*;
import java.util.*;
import tikape.db.Database;
import tikape.dom.Tuote;
public class TuoteDao implements Dao<Tuote, Integer> {
private Database database;
public TuoteDao(Database database) {
this.database = database;
}
@Override
public Tuote findOne(Integer key) throws SQLException {
try (Connection conn = database.getConnection()) {
PreparedStatement s = conn.prepareStatement("SELECT * FROM Tuote WHERE id = ?");
s.setInt(1, key);
ResultSet rs = s.executeQuery();
// tee jotain tuloslistalla
}
return null;
}
// ....
Lopulta pääohjelmassa toiminnallisuus näyttää esimerkiksi seuraavanlaiselta:
if (System.getenv("PORT") != null) {
port(Integer.valueOf(System.getenv("PORT")));
}
String jdbcOsoite = "jdbc:sqlite:kanta.db";
if (System.getenv("DATABASE_URL") != null) {
jdbcOsoite = System.getenv("DATABASE_URL");
}
Database db = new Database(jdbcOsoite);
TuoteDao tuoteDao = new TuoteDao(db);
get("/tuote/:id", (req, res) -> {
HashMap map = new HashMap<>();
map.put("tuote", tuoteDao.findOne(Integer.parseInt(req.params("id"))));
return new ModelAndView(map, "sivu");
}, new ThymeleafTemplateEngine());
Koeasiaa
Kurssikokeessa on kolme tehtävää, joissa jokaisessa saattaa olla yksi tai useampi alitehtävä. Kokeeseen ei tule Java-ohjelmointia tai Web-sovellusten ohjelmointia. Tästä huolimatta näistä on tärkeää ymmärtää se, että tietokannanhallintajärjestelmät ovat tyypillisesti erillisiä niitä käyttävistä sovelluksista.
Aiemmissa tietokantojen perusteiden kurssikokeissa ovat esiintyneet ainakin kurssilla esiintyneiden käsitteiden (ml. harjoitukset) selitystehtävät, erilaiset käsiteanalyysi- ja tietokantataulujen suunnitteluun liittyvät tehtävät, sekä sql-tehtävät.
Osoitteessa https://docs.google.com/document/d/1lkdEBSg9nhdFUhgnVXl6jtsZuI0ODy-Kye_cag3qmu4/edit?usp=sharing löytyy vanha kurssikoe, jota voi käyttää osana tenttiin kertausta.
Kokeeseen saa ottaa mukaan "lunttilapun". Lunttilappu on kaksipuolinen, A4-kokoinen, itse käsin täytetty paperi. Lunttilappuun tulee merkitä nimi ja opiskelijanumero, ja se tulee jättää kokeen palautuksen yhteydessä tenttivalvojille.